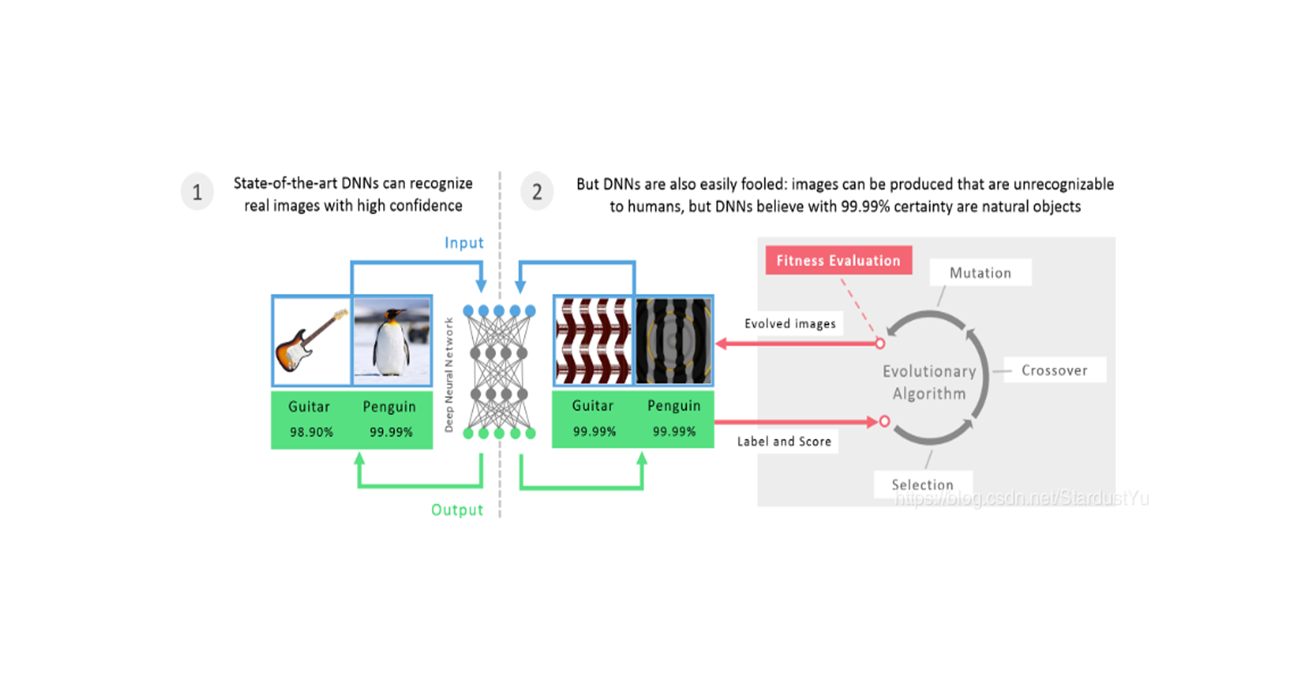
一、论文相关信息
1.论文题目
Explaining and Harnessing Adversarial Examples
2.论文时间
2015年
3.论文文献
https://arxiv.org/abs/1412.6572
二、论文背景及简介
早期对对抗样本产生的原因的猜测集中于神经网络的非线性性和过拟合,但是这篇论文证明神经网络的线性性质是造成神经网络具有对抗样本的主要原因。同时,这篇论文提出了一个能供更简单与更快速的生成对抗样本的方法。
三、论文内容总结
- 否定了对抗样本是因为非线性和过拟合导致的,认为对抗样本是因为神经网络在高维空间的线性导致的,并提出了大量的实验加以说明。对抗样本可以被解释成高维空间点乘的一个属性,他们是模型太过于线性的结果。
- 模型的线性让其更容易被训练,而其非线性让其容易抵御对抗扰动的攻击,即容易优化的模型也容易被扰动。
- 提出了一种特别快的生成对抗样本的方法FGSM:
- FGSM的实质是输入图片在模型的权重方向上增加了一些扰动(方向一样,点乘最大)。这样可以让图片在较小的扰动下出现较大的改变,从而得到对抗样本。
- 不同模型之间的对抗性示例的泛化可以解释为,对抗性扰动与模型的权重向量高度一致,不同模型在训练执行相同任务时学习相似的函数
- 提出了一种基于FGSM的正则化方法,对抗训练可以用来正则化,甚至效果比dropout还要好。
- 相比于模型融合,单个模型的对抗防御能力更好一些,集成策略不能够抵御对抗样本
- 线性模型缺乏抵抗对抗性扰动的能力;只有具有隐藏层的结构(在普遍近似定理适用的情况下)才应该被训练来抵抗对抗性扰动。
- RBF网络可以抵御对抗样本
- 对抗样本的分布特征,即对抗样本往往存在于模型决策边界的附近,在线性搜索范围内,模型的正常分类区域和被对抗样本攻击的区域都仅占分布范围的较小一部分,剩余部分为垃圾类别(rubbish class)
- 垃圾类别样本是普遍存在的且很容易生成,浅的线性模型不能抵御垃圾类别样本,RBF网络可以抵御垃圾类别样本
附:如需继续学习对抗样本其他内容,请查阅对抗样本学习目录
四、论文主要内容
1、Introducttion
该论文否定了L-BFGS中对对抗样本出现的原因的解释,认为神经网络高维空间的线性行为很容易造成对抗样本,作者还提出,常规的正则化策略如dropout、预训练、模型平均等并不能显著降低模型在对抗样本中的脆弱性,但将模型换成非线性模型族如RBF网络就可以做到这一点。
我们的解释表明,模型由于线性而容易训练,而又因非线性而容易抵御对抗扰动的攻击,这两个问题之间是对立的。从长远来看,通过设计更强大的优化方法,成功地训练出更多的非线性模型,也许可以避免这种矛盾。
2、Releated Work
主要介绍了一些之前的对对抗样本产生原因的猜测,这里不做细致说明
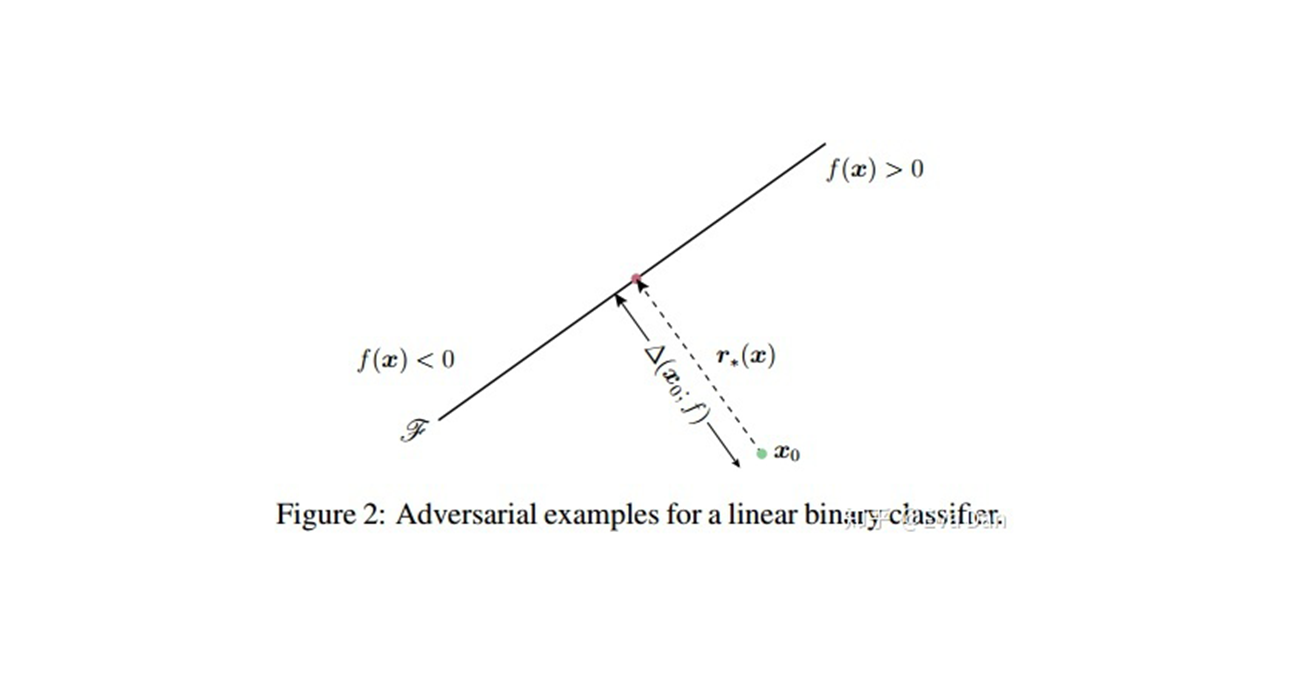
3、The Linear Explanation Of Adversarial Examples
在这一节主要解释了,作者为什么说是因为模型的线性而产生的对抗样本。
我们知道,输入图像通常都是8bits的,这也就丢失了输入图像的1/255之间的信息。而如果对抗扰动足够小的话,是会被忽略的,因此作者猜测,是由于模型的线性所导致的。作者通过数学公式来解释。一个网络模型的权重为$ w^T$
对抗扰动让网络的激励增加了$ w^T\eta$ ,我们只要将$ \eta=sign(w)$ ,就可以最大化的增加模型的激励,当$ w^T$ 具有n维,平均权重值为m,那么激励就会增长$ \epsilon mn(||\eta||_{\infty}<\epsilon)$ ,但是$ ||\eta||_{\infty}$ 却并不会因为维度的增加而增加,这样,当我们增加一个很小的扰动的时候,就会产生很大的改变。这被称为”accidental steganography”,这种隐藏术的意思是,一个线性模型被迫只关注与权重相接近的信号,却会忽略那些权重大但不相关的振幅(像素点)。
上述的解释说明,对一个简单的线性网络来说,如果他的输入有着足够的维度,那么他就会有对抗样本。先前对对抗样本的解释引用了了神经网络的假设特性,例如它们假定的高度非线性性质。我们基于线性的假设更简单,也可以解释为什么softmax回归容易受到对抗性例子的影响。
4、Linear Perturbation of Non-Linear Models
从对抗样本的线性视角来看,我们得出了一个很快的生成对抗样本的方法。我们假设神经网络是十分线性的。
我们已知的一些模型,LSTM、ReLU、maxout网络都是被设计用线性的方式来运作的,所以比较容易优化,而非线性的模型,比如Sigmoid网络,我们会很难优化。但是线性,会让模型更容易受到攻击。
模型的参数设为$ \theta$ ,$ x$ 记为模型的输入,$ y$ 记为模型得到的标签,$ J(\theta,x,y)$ 记为神经网络使用的损失函数,同门可以通过以下的公式来得到对抗扰动:
我们把这个叫做FGSM(fast gradient sign method)
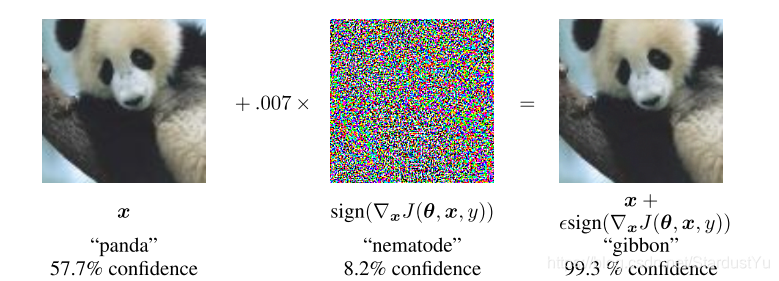
作者在使用中,使用了$ \epsilon=0.25$ ,在MINST测试集上,对softmax分类器攻击达到了99.9%的攻击成功率,平均置信度为79.3%。使用相同的配置,对maxout网络,能达到89.4%的攻击成功率,平均置信度为97.6%。当使用卷积maxout网络与CIFAR-10数据集时,使用$ \epsilon=0.1$,达到了87.15%的攻击成功率,以及96.6%的平均置信度。同时,作者发现,使用其他的简单的方法也可以产生对抗样本,比如使x在梯度方向上旋转一定的角度,就可以产生对抗样本。
5、Adversarial Training Of Linear Models Versus Weight Decay
我们拿最简单的模型Logistic回归为例。我们通过这个例子来分析如何生成对抗样本。
我们的模型是用$ P(y=1)=\sigma(w^Tx+b)$ 辨别标签$ y\in{-1,1}$ 。使用梯度下降的训练过程可以描述为:
其中$ \zeta(z)=log(1+exp(z))$ 。通过这个模型,我们来得到一个对对抗样本训练的模型。
对模型而言,梯度的符号其实等于$ -sign(w)$ ,而$ w^Tsign(w)=||w||_1$。所以,对于对抗样本来说,我们要做的就是最小化如下模型:
仔细观察这个模型,你会觉得,这个公式很像L1正则化后的公式,但又有些不同,L1正则化是加上$ \epsilon||w||_1$ ,而我们得到的是减去该式子,作者也将该方法称为$ L^1$ 惩罚。但是,当模型的$ \zeta$ 饱和,模型能够做出足够自信的判断的时候,该方法就会失效,该方法只能够让欠拟合更严重,但不能让一个具有很好边界的模型失效。
而且,当我们将该方法转移到多分类softmax回归时,$ L^1$ weight decay 会变得更糟糕,因为它将softmax的每个输出视为独立的扰动,而实际上通常无法找到与类的所有权重向量对齐的单个η。在具有多个隐藏单元的深层网络中,该方法高估了扰动可能造成的损害。因为,$ L^1$ weight decay高估了一个对抗样本所能造成的危害,所以有必要将$ L^1$ weight decay的系数设置的更小。更小的系数时训练能够更成功,但也让正则化效果不好。作者实验发现,对第一层来说,$ L^1$ weight decay的系数设置为0.0025时都有些过大。但作者在MNIST训练集上训练maxout网络使用0.25的系数却获得了很好的结果。?????很迷。
六、Adversarial Training Of Deep Networks
深度模型并不像浅的模型那样,它能够表示出能够抵抗对抗样本的函数。广义逼近定理(the universal approximator theorem)证明至少有一层隐藏层的神经网络能够任意精度的表示任何函数,只要他有足够的单元。而浅层线性模型既不能在训练点附近保持不变,又能将不同的输出分配给不同的训练点。
当然,广义逼近定理并没有说明训练算法是否能够发现具有所有期望性质的函数。很明显的,标准的监督学习并没有具体说明,选择的函数能够抵御对抗样本。这必须在训练程序中编码才行。
使用对抗样本做数据增广可以暴露模型概念化决策函数上的缺陷,而且,从没被证实,该方法在一个SOTA模型上的提升效果可以超过dropout。然而,这部分是因为很难对基于L-BFGS的昂贵的对抗样本进行广泛的实验。
基于FGSM的对抗训练是一个很有效率的正则化方法:
在实验中,使用$ \alpha=0.5$ 。这个方法的意思时我们持续的生成对抗样本来保证我们的模型可以抵御攻击。
七、Different Kinds Of Model Capacity
作者认为,处于三维空间的我们很难对高维空间有认识,因此,我们没法看出在高维空间中小的改变是如何产生一个大的影响的。
许多人认为,低容量的模型很难做出很多不同的自信的预测,但这是不正确的。作者拿具有低容量的RBF网络为例,$ p(y=1|x)=exp((x-\mu)^T\beta(x-\mu))$ ,RBF网络只能够预测在$ \mu$ 范围内的正类,但是对其他范围就具有低的预测置信度,这让RBF网络天生就不易受对抗样本的影响,因为,当RBF被攻击时,它具有较低的置信度。一个没有隐藏层的RBF网络,在MNIST数据集上,使用FGSM方法进行攻击,具有55.4%的攻击成功率。但是,它在误分类样本上的平均置信度只有1.2%。而在干净的测试集上的平均置信度有60.6%。低容量的模型确实不能够在所有的点上都能够正确的分类,但是它却可以在一些不能理解的点上,给予较低的置信度。
我们可以将线性单元和RBF单元看作是精确召回折衷曲线上的不同点。线性单元通过在某个方向上响应每一个输入来实现高召回率,但由于在不熟悉的情况下响应太强,因此可能具有较低的精度。RBF单元只对空间中的某个特定点做出响应,但这样做会牺牲召回率,从而获得较高的精度。基于这一思想,我们决定探索包含二次单元的各种模型,包括深RBF网络。我们发现这是一个非常困难的任务模型,当使用SGD训练时,具有足够的二次抑制以抵抗对抗性扰动,获得了较高的训练集误差
八、Why Do Adversarial Examples Generalize
一个模型生成的对抗样本,会被一些具有不同的架构或者由不同训练集上训练出来的模型错误分类,而且会错误分类成一种类别。但基于极端非线性和过拟合,没法解释这种行为。因为,在这两种观点中,对抗样本很常见,但只发生在特别精确的位置上。
而从线性的角度来看,对抗样本会出现在广阔的子空间中。只要$ \eta$ 在损失函数的梯度方向上点积,$ \epsilon$ 足够大,一个模型就会被该对抗样本所愚弄。
作者以$ \epsilon$ 的值为变量,做了实验,来进行证明。
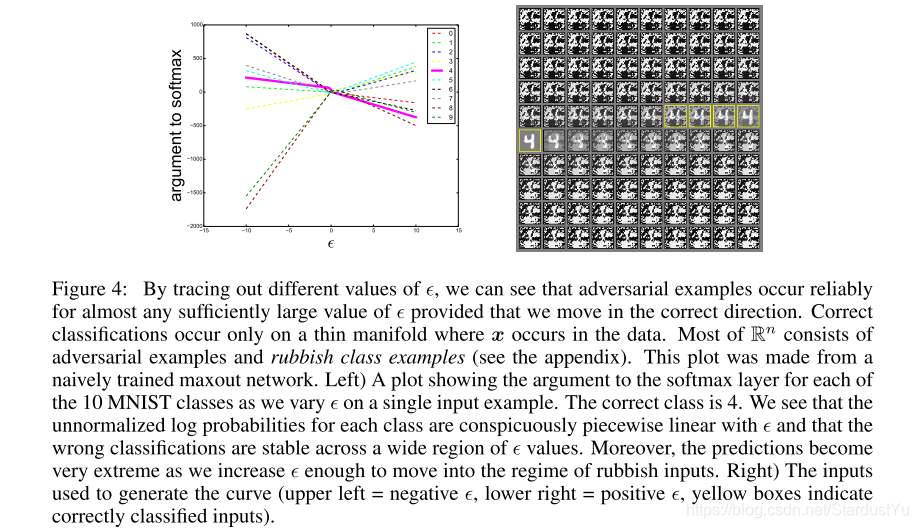
作者发现,对抗样本出现在连续的一维空间区域,这也就对应了上述的解释。
为了解释,多个分类器会将对抗样本分类成相同的类,他们假设目前方法所训练的神经网络看起来都像是在同一个训练集上训练出来一样。在训练集的不同子集上训练时,这些分类器能够学习到近似相同的分类权值。而这是因为机器学习的泛化能力。而根本的分类权值的稳定性又能反过来影响对抗样本的稳定性。
为了测试这一假设,作者又进行了如下的实验。作者在一个maxout网络上生成了对抗样本,然后用一个浅的softmax网络和RBF网络去分类这些样本。这里作者讨论了这两个浅的网络对 那些被maxout网络分类错误的对抗样本 进行分类所花费的时间。然后作者通过实验发现RBF花费的去适配这些分类错误时间更少,是因为RBF是线性的,也就是说,线性的模型更容易被迁移的攻击,也就是说,线性造成了模型之间的泛化。
九、Alternative Hypotheses(其他的假设)
在这一节,作者主要介绍了对对抗样本存在性的一些其他假设。
第一个要说的假设是,生成训练可以在训练过程中提供更多的限制条件,或者使模型学习如何区分“真实”和“虚假”数据,并且只对“真实”数据有高的置信度。文章表明,某些生成训练并不能达到假设的效果,但是不否认可能有其他形式的生成模型可以抵御攻击,但是确定的是生成训练的本身并不足够。
另一个假设是,相比于平均多个模型,单个模型更能够抵御对抗样本的攻击。作者做了实验证明了这个假设。作者在MNIST训练集上训练了12个maxout模型进行集成,每一个都使用不同的随机数种子来初始化权重,使用了dropout,minibatch的梯度下降,在对抗样本攻击的时候,具有91.1%的攻击成功率。但是当我们使用对抗样本攻击集成模型中的一个模型的时候,攻击成功率下降到了87.9%。
十、Summary
- 对抗样本可以被解释成高维空间点乘的一个属性,他们是模型太过于线性的结果。
- 不同模型之间的对抗性示例的泛化可以解释为,对抗性扰动与模型的权重向量高度一致,不同模型在训练执行相同任务时学习相似的函数
- 最重要的是扰动的方向,而不是空间中的特定点。对抗样本在空间内,并不是像空间中的有理数那样平铺的。
- 因为最重要的是扰动的方法,所以对抗扰动也可以在不同的训练集上进行泛化
- 我们介绍了一组可以快速生成对抗样本的方法(FGSM)
- 我们证明了,对抗训练可以用来正则化,甚至效果比dropout还要好
- 容易优化的模型也容易被扰动
- 线性模型缺乏抵抗对抗性扰动的能力;只有具有隐藏层的结构(在普遍近似定理适用的情况下)才应该被训练来抵抗对抗性扰动。
- RBF网络可以抵御对抗样本
- 训练来模拟输入分布的模型不能够抵御对抗样本
- 集成策略不能够抵御对抗样本
- 对抗样本的分布特征,即对抗样本往往存在于模型决策边界的附近,在线性搜索范围内,模型的正常分类区域和被对抗样本攻击的区域都仅占分布范围的较小一部分,剩余部分为垃圾类别(rubbish class)
- 垃圾类别样本是普遍存在的且很容易生成
- 浅的线性模型不能抵御垃圾类别样本
RBF网络可以抵御垃圾类别样本
使用一个设计成足够线性的网络——无论是ReLU或maxout网络、LSTM,还是经过精心配置以避免过多饱和的sigmoid网络——我们能够解决我们关心的大多数问题,至少在训练集上是这样。对抗样本的存在表明,能够解释训练数据,甚至能够正确标记测试数据并不意味着我们的模型真正理解我们要求他们执行的任务。相反,他们的线性反应在数据分布中没有出现的点上过于自信,而这些自信的预测往往是非常错误的。这项工作表明,我们可以通过明确地识别问题点并在每个问题点上修正模型来部分地纠正这个问题。然而,我们也可以得出这样的结论:我们使用的模型族在本质上是有缺陷的。优化的容易程度是以容易被误导的模型为代价的。这推动了优化程序的发展,这些程序能够训练行为更局部稳定的模型