一、对抗领域背景介绍
1、出现背景
深度模型的脆弱性问题逐渐的暴露出来,一个人类无法察觉的对抗扰动却能轻易的让深度模型分类错误,这个问题导致深度模型无法应用在对安全有严格要求的领域。
2、当前攻击方法现状
- L-BFGS:首个攻击方法,采用L-BFGS寻找扰动,效果差,速度慢
- FGSM:基于梯度的攻击方法,速度快,但效果一般,在MNIST上扰动都很明显
- PGD:FGSM的迭代版本
- BIM&ILLC:迭代的攻击方法
- Deepfool:得到更小的扰动,比FGSM小一个量级
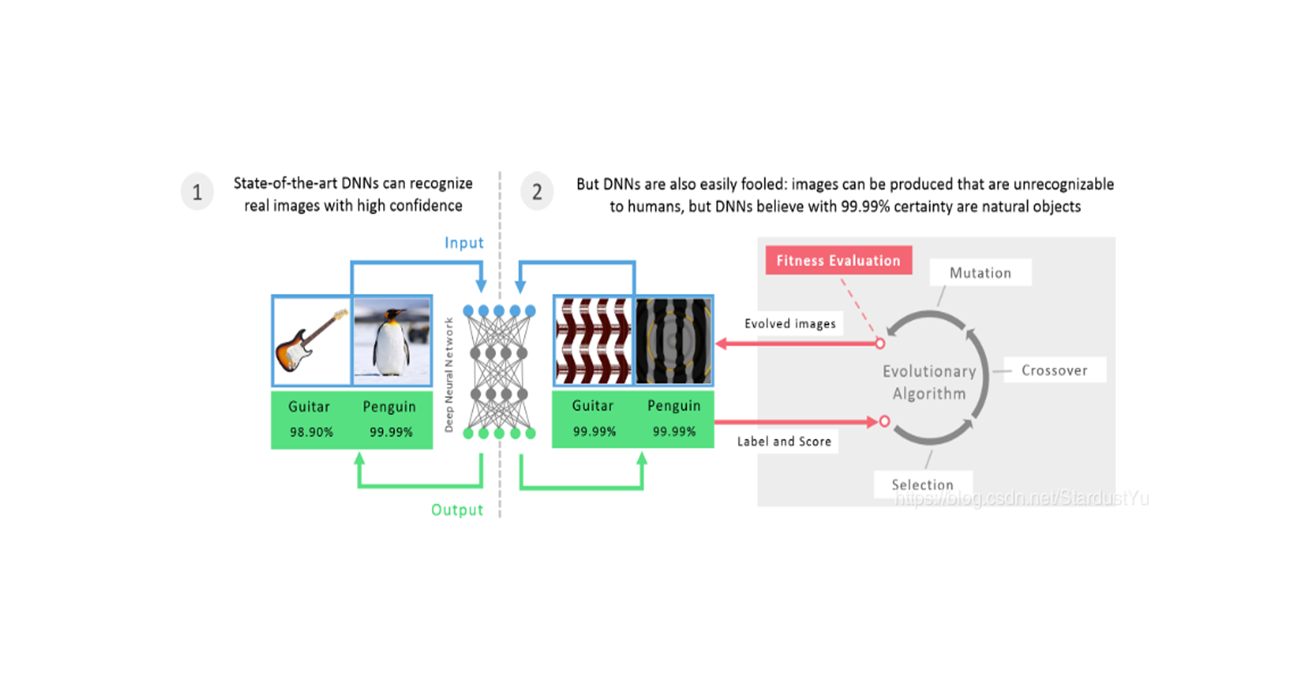
- CPPN EA Fool:采用进化算法生成图片,假正例攻击
- JSMA:借用Jacobian矩阵来生成对抗样本
- C&W’s Attack:重新设计对抗目标,平滑了box-constrained,采用了三种距离攻击,针对蒸馏防御
- ZOO:使用梯度估算,直接进行黑盒攻击
- Universarl Attack:生成一个普适性的对抗扰动
- One pixel Attack:修改一个像素实现攻击效果
- Feature Adversary:借用网络内部特征设计目标方程
- Hot&Cold:提出了新的对抗样本量化方法PASS,来进行对抗攻击
- Natural GAN:借用GAN网络生成一个更加自然的攻击方法
3、当前防御方法现状
- Defensive Distillation:采用蒸馏方法提高模型的鲁棒性。被C&W’s attack解决
- BReLU:修改了ReLU激活函数
- 对抗训练:将对抗样本加入训练集中增加模型的容量,但是对CIFAR-10这样复杂的数据集效果不好
- 对抗检测:训练网络来检测对抗样本
- 测试和验证方法
二、Towards Robust Neural Networks via Random Self-ensemble
时间:2018年
关键词:Random Self-Ensemble防御方法
论文位置:https://arxiv.org/abs/1712.00673
引用:Liu X, Cheng M, Zhang H, et al. Towards robust neural networks via random self-ensemble[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 369-385.
1、主要思想
提出了一个新的防御方法,Random Self-Ensemble(RSE),结合了随机性和集成度这两个重要部分。RSE为网络添加随机的噪声层来阻止梯度攻击,将随机噪声与预测结合起来来稳定性能。
模型集成可以提高鲁棒性,但也会增加模型的大小。我们可以构建了无限个噪声模型$ f_{\epsilon}$ ,通过集成模型的结果来提高鲁棒性。但是,我们都知道在推断阶段增加噪声只会让效果变差,那么集成的效果也不确定。所以作者的做法是在训练阶段加入噪声层,这样,训练阶段的目的就是最小化模型损失的上界,噪声带来的影响就可控,因此算法的性能也就比较好。同时,由于噪声层会生成随机的噪声,这样RSE方法就等价于无限个噪声模型。在测试时,预测10次(10个模型的结果达到饱和),取平均。
RSE添加噪声层来训练网络的方法,等价于添加了一个额外的Lipschitz正则化。
在每次经过噪声层时,输入向量变为$ x = x+\epsilon,\epsilon$ 随机生成。


在计算$ w$ 的梯度时,需要使用$ \epsilon$ 来计算。
2、算法性能
1)防御性能
在CIFAR-10和VGG网络(92%的准确率)下,使用C&W攻击可使其准确率下降至小于10%,当前最好的防御方法能提高到48%的准确率,RSE方法可以提高到86%的准确率。

2)噪声添加位置

3、评论&想法
三、Ground-Truth Adversarial Examples
时间:2018年
关键词:攻防技术的评估、基于网络验证
论文位置:https://openreview.net/forum?id=Hki-ZlbA-¬eId=Hki-ZlbA-
引用:Carlini N, Katz G, Barrett C, et al. Ground-truth adversarial examples[J]. 2018.
1、背景
近年来,各种攻击防御方法层出不穷,总会有更strong的攻击方法来破解目前的防御方法,这些提出了一个问题,在设计防御方法的过程中,如何去评估其对未来的攻击方法的鲁棒性?
2、主要思想
提出了ground truth的概念,ground truth:离输入样本最近的但分类不同的样本(对抗样本)。借用ground truth来评估攻击方法的能力。比较攻击得到的对抗样本与ground truth的距离、防御前后得到的对抗样本与ground truth的距离。ground truth的作用如下:(1)如果我们知道了一组点的ground truth,我们就可以评价一个网络针对攻击的鲁棒性。(2)通过测量对抗样本到ground truth的距离,评估攻击方法。(3)通过计算新的ground truth评估防御方法的效率。
1)Ground Truth的寻找
对于一个网络$ F$ ,我们设定其距离评价标准为$ d\in {L_1,L_\infty}$ ,输入点为$ x$ ,目标标签为$ t’\ne F(x)$ ,初始GroundTruth点为$ x’_{init}$ ,我们要找到一个点$ x_{t’}$ ,满足$ F(x_{t’})=t’,d(x,x_{t’})$ 最小。$ x’_{init}$ 是用CW attack方法来得到。在这里使用了网络验证技术Reluplex来验证网络的特性。

3、算法性能
1)攻击评测
使用了MNIST数据集的10个样本点,每个样本可以被攻击为9类,所以总共有90个样本示例,下图中Points点的数目表示上面的搜索算法成功停止的比例,即能在样本和对抗样本之间找到更小的距离的Ground Truth的比例,CW表示到对抗样本点的平均距离,Ground Truth表示样本点到Ground Truth的平均距离(越远越好)。其中N表示一个全连接层网络,$ \bar{N}$ 表示对抗训练后得到的网络

2)防御评测

可以看到,对抗训练是有效的,他将Ground Truth从0.04提高到了0.171。
4、评论&想法
- 采用Reluplex进行验证,对输入点的数目要求严格,只能用于小模型上,而且,寻找过程花费时间过多,平均每次迭代需要2~3小时。