一、论文相关信息
1.论文题目
ZOO: Zeroth order optimization based black-box atacks to deep neural networks without training substitute models
2.论文时间
2017年
3.论文文献
https://arxiv.org/abs/1708.03999
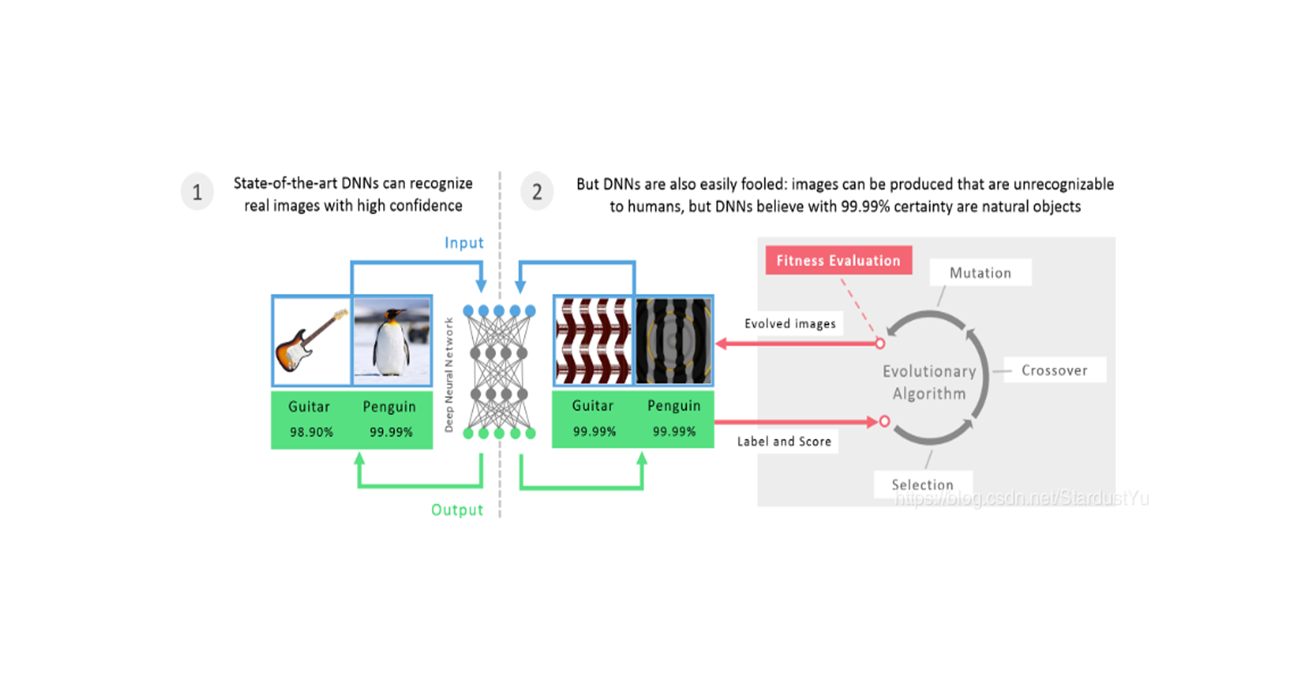
二、论文背景及简介
之前的黑盒攻击方式都是利用了对抗样本的迁移性特性,由替代模型生成,再迁移到另外一个网络,ZOO提出了一种新的黑盒攻击方法,在没有用到替代模型的同时,直接攻击黑盒模型,仅仅直到黑河模型的输入和输出(置信度)。
ZOO使用了零阶随机坐标下降、降维、多尺度攻击、重要性采样技术来进行攻击。利用零阶优化方法,可以实现对目标DNN的改进攻击,减少了对替代模型的训练,避免了攻击可转移性的损失。
实验得知,提出的ZOO攻击与最新的白盒攻击一样有效,并且显著优于现有的通过替代模型进行迁移而得到的黑盒攻击。
三、论文内容总结
- 提出了一种梯度估算的方法,在C&W attack的基础上,通过梯度估算以及coordinate 下降方法来对样本进行更新,进而实现黑盒攻击。
- 这种黑盒攻击方式,在每次迭代过程中,需要对$ p$ 维的图像的每一个维度进行梯度估算,代价太大,提出了以下几种优化方法。
- 第一种优化方法就是对扰动进行降维,通过对一个维度低的数据进行更新,并将该数据通过转变转换成对应维度的扰动,来得到扰动值。
附:如需继续学习对抗样本其他内容,请查阅对抗样本学习目录
四、论文主要内容
1. Introduction
A. Adversarial attacks and transferability
简要介绍了之前的攻击方法
B. Black-box attacks and subsitute models
介绍了白盒攻击、黑盒攻击还有”no-box” attack(连模型的输入和输出都不知道的情况)
介绍了subsitute model的概念,即根据黑盒模型的输入和输出训练出一个subsitute model。可以对其进行白盒攻击,再进行迁移。
C. Defending adversarial attacks
介绍了一些对抗防御的方法
对抗样本检测:这种方法非常依赖于对抗样本的分布,如果别的对抗样本与训练集的分布不同的话,这种方法就会失效。
Gradient and representation masking:因为很多攻击方法都是基于梯度来进行的,所以一个很自然的想法就是通过gradient masking,即在训练阶段隐藏梯度信息。网络蒸馏就属于这类方法。representation masking是用鲁棒的representations(例如高斯操作或RBF核)来取代DNN的内部representations(通常是网络最后几层)
对抗训练:对抗训练的原理是,通过加入对抗样本,来使得网络对小的扰动不再那么敏感。通过迭代性的数据增强核retraining,可以增强网络的鲁棒性。这也表明,DNN可以以增加网络容量(增加模型参数)的代价来提高网络的鲁棒性。
D. Black-box attack using zeroth order optimization:benefits and challengs
零阶方法是一种不需要进行梯度计算的优化方法,在优化过程中仅仅需要零阶的值(f(x)),也就是根据两个零阶值($ f(x+hv),f(x-hv)$)来估计梯度,其中$ v$ 表示梯度方向,$ h$ 表示的是两个值的距离。
那么根据上面的估计方法,我们就可以采用梯度下降方法了,其收敛性也已经被证实了。
当时用这种方法应用到黑盒攻击时,我们不需要再训练一个substitute model了,所以比较方便。
零阶方法在对每个像素点的梯度进行估计时,需要进行两次优化过程。所以,当黑盒模型的输入图片很大时,例如Inception-v3的输入为299x299x3。我们在一次迭代过程中需要处理299x299x3x2次优化,而且可能要经过很多次的迭代运算,这样做的代价将会非常巨大。
为了解决上面的问题,作者提出了coordinate descent方法,通过有效率的更新坐标系,能够加速攻击过程。而且在计算中,作者采用了batch梯度下降的思想。
E. Contributions
- 提出了一种使用零阶方法的coordinate descent方法,能够有效率的攻击黑盒模型,提高了黑盒攻击的成功率。
- 为了降低在大型模型上的计算时间和计算量,提出了attack-space dimension reduction,hierarchical attacks,importance sampling
- 证明了在大模型上(例如Inception-v3),我们的方法可以在可接受时间内得到一个成功的对抗样本。
2. Related Work
简要介绍了一下对抗样本出现的意义,以及ZOO方法的优缺点,以及与C&W‘s attack和JSMA的对比
3.ZOO
A. Notation for deep neural network
记$ F(x)$ 表示目标网络,其输入$ x \in \mathbb{R}^p$ ,输出$ F(x) \in [0,1]^K$
B. Formulation of C&W attack
本文的黑盒攻击方法是受C&W 攻击方法的启发得到的,所以这里提一下其公式。
给定样本$ x_0$ ,令$ x$ 表示对抗样本,$ t$ 表示目标类别,那么C&W的公式如下:
$ ||x-x_0||_2^2$ 是一个正则化项,用来规范扰动的大小。第二个项$ c·f(x,t)$ 时loss项,反映的是对抗攻击的不成功的程度。这里采用的损失函数是:
使用$ \frac{1+tanh w}{2}$ 替换$ x$ ,只需要对$ w$ 进行预测,解决了box-constraint的限制。
C. Proposed black-box attack via zeroth order stochastic coordinate descent ZOO方法
把C&W attack直接用到黑盒攻击有什么限制呢?1.其损失函数$ f(x,t)$ 用到了logtis,这是模型的内部信息。2.对目标函数优化需要用到梯度下降,而我们得不到梯度。
我们基于这两个问题,提出了一些解决措施,首先,修改我们的损失函数$ f(x,t)$ ,使其只用到模型输出$ F$ 和目标类别$ t$ 。其次,用有限差分法估计梯度。下面就是对这两种方法的详解
损失函数的修改
就是将原目标函数修改为$ f_2$ ,并做了简单的修改:
log操作对我们的黑盒攻击来说是非常必要的,因为总会有一些训练的很好的DNN,在输出上产生一个倾斜的概率分布,这样一个类别的置信度会远远大于其他类别的置信度。而log操作可以降低这个带来的影响。
如果将该目标函数用在无目标攻击上,我们可以将其修改为:
零阶优化的使用
这里使用了对称分量来进行对梯度的估计:
其中,$ h$ 是一个小的常数,实验中取$ h = 0.0001$ 。$ e_i$ 是一个标准基向量,在第$ i$ 个分量上取1。这种方式得到的梯度误差大约为$ O(h^2)$ ,太过精准的梯度往往没那么必要(比如FGSM只使用了梯度的方向)。
每一次计算梯度,都需要运行两次网络来得到$ f(x+he_i)$ 和$ f(x-he_i)$ 。
对于任意一个样本$ x \in \mathbb{R}^p$ ,我们需要评价目标函数$ 2p$ 次,来估计全部的$ p$ 个维度特征的梯度。当我们使用一次以上的目标函数评价时,我们还可以得到其海森估计:
对于一张图片来说,在整体运算过程中,$ f(x)$ 只运行一次即可,也就是说计算梯度和海森估计的计算代价是一样的。
对于这样一个想法来说,如果输入图片为64x64x4,那么我们一轮梯度下降过程,需要计算64x64x3x2次目标函数评价,而若想要收敛,还需要进行很多轮梯度下降,所以说,这种方法的代价是巨大的。那么为了解决上面的问题,作者选择了coordinate-wise update方法。
Stochastic coordinate descent
在每次迭代过程中,首先,我们先随机的选择一个变量(坐标维度),通过沿该坐标近似最小化目标函数的方向更新图像,其思想如下:

那么上面思想最难的一部分那就是步骤3。
在对$ x_i$ 估计完梯度和二阶梯度后,我们可以用任意一种一阶或者二阶的方法来找到最好的$ \delta$ 。一阶方法,作者推荐ADAM方法,作者也使用了牛顿迭代法,这种方法使用了一阶梯度和二阶梯度,注意,当二阶梯度为负数时,我们只简单的用他的梯度来更新$ x_i$ 。
ADAM方法如下:

牛顿迭代法如下:

注意:我们使用上面这种方法时,每轮迭代只更新了一个坐标维度。为了实现GPU的资源利用,作者采用了batch估计的方法,也就是一次迭代处理一个batch,每个batch中包含多个坐标维度。实验中作者选中batch为128。
D. Attack-space dimension reduction 扰动降维
在每一个迭代过程中,我们都需要对$ x$ 的每一个像素点都进行梯度估计,然后更新,这耗费的时间太多了。所以提出了一种对扰动进行降维的方法,记扰动为$ \Delta x =x - x_0 = D(y) $ ,其中$ \Delta x = D(x) \in \mathbb{R}^p$ ,$ y \in \mathbb{R}^m,m<p$ 。$ D$ 是一种维度变形函数,能够将$ m$ 维的数据转换成$ p$ 维的。
有了这样的定义,那么我们只需要对$ y$ 的每一个维度进行梯度估计就可以了,即:
函数$ D$ 的一个简单的形式,就是对$ y$ 进行双线性插值,将其resize成$ p$ 维的图像。
在Inception-v3网络我们可以将原图像$ p$ =299x299x3的图像,转换成$ m=$ 32x32x3维的。这样能够极大的减少计算量。
当然,函数$ D$ 会有更多的其他的形式,比如DCT
E. Hierarchical attack 多尺度攻击
当我们用上面的方法进行攻击的时候,出现了一个问题,那就是随着搜索空间的减小,我们很有可能找不到一个合适的扰动,而增大搜索空间就有可能找到,但却又增加了计算量。于是,作者提出了多尺度攻击。
多尺度攻击的思想如下:首先我们先选择一个比较小的$ m_1$ ,其对应的变换函数为$ D_1$ ,用这两个参数进行目标函数的更新,随着迭代次数的进行,当损失函数不再下降时,我们增大搜索空间,使用一个较大的$ m_2$ ,与其对应的变换函数$ D_2$ ,再进行目标函数的更新,直到我们找到一个对抗样本。
其对应的$ y_j$ 的变换形式为$ y_j = D_i^{-1}(D_{i-1}(y_{j-1}))$ ,其中$ D_i^{-1}$ 表示$ D_i$ 的逆变换,即将$ p$ 维转换成$ m_i$ 维。
F. Optimize the important pixels first 重要性采样
当我们采用coordinate进行更新时,每次我们都随机的选择某个coordinate,但是在一个coordinate的计算过程的代价也是比较大的,为了减少这部分的代价损失,提出了重要性采样,也就是先对一些比较重要的coordinate进行计算,这样样本就能够在较少的计算时就能够找到对抗样本。
作者认为,图像边缘和角落的像素点是并不那么重要的,靠近主要物体的像素点才是最重要的。所以,在攻击时,我们会采样那些靠近主要物体的像素点。
我们建议将图像分成8×8个区域,并根据该区域像素值变化的大小来分配采样概率。我们对每个区域中的绝对像素值变化进行最大池化,将样本上采样到所需的维度$ m$ ,然后对所有值进行归一化,使其总和为1。
几轮迭代后,我们会根据最近的变化来更新采样概率。
当attack-space比较小,比如32x32x3的时候,作者没有采用importance sampling,当attack-space增大到到一定值得时候,就会使用importance sampling。
4. Performance Evaluation 实验部分
A. Setup
实验发现,作者得ZOO方法在成功率和扰动大小方面,跟C&W attack表现相似。且在黑盒攻击方法,其表现远超基于substitute model的黑盒攻击方法。
B. MNIST and CIFAR 10
下面将会对ZOO、C&W attack 和 基于substitue model 的黑盒攻击进行对比
模型选择
C&W attack采用了原论文中的模型,ZOO也是用的这个模型
数据集选择
在有目标攻击中,每个数据集,作者选择了100张图片,对每个图片都进行9个目标的攻击,共得到900张对抗样本。在五目标攻击中,作者在每个数据集上选择了200张图片。
参数设置
在ZOO和C&W attack的c值选择上,我们从0.01开始,进行了9次二分查找,直到100轮迭代后,loss不再降低才停下来。
ADAM参数选择为$ \eta=0.01,\beta_1=0.9,\beta_2=0.999$
C&W attack 进行了1000轮迭代。ZOO在MINST进行了3000轮迭代,在CIFAR上进行了1000轮迭代。注意:我们的模型更新的慢的原因是,在每轮迭代中,我们只更新了128个像素点。
在MINST和CIFAR上,作者没有进行attack-space降维,也没有用多尺度攻击和重要性采样。
在基于substitue model上,作者采用了150折留出的方法从测试集得到图片,运行了5次Jacobian数据增强epoch,设置数据增强的参数为0.1。并使用了FGSM和C&W的攻击方法。在FGSM上,采用$ \epsilon=0.4$ ,C&W,采用$ k = 20$ 。
其他trick
当我们攻击MNIST时,我们发现,当使用tanh函数来替换$ x$ 时,在像素点$ 0,1$ 的边界区域,会出现梯度消失的问题,因为梯度估计不太准确,所以梯度会容易消失。于是,在更新MNIST时,作者采用了box-constraints的方法,而没有用tanh进行替代。而CIFAR 10没出现这个问题。
结果

C.. Inception network with Image Net
在Inception-v3这样的大模型下,很难训练出一个好的substitute model,这需要model有一个大的容量,需要进行大量的Jacobian数据增强来得到大量的数据,是很不切实际的。同时,用迁移性得到的攻击的准确率很低,特别是有目标攻击,成功率更低。
对Inception-v3的无目标攻击
在数据集选择上,作者使用了ImageNet的150张图片。使用到了attack-space降维和重要性采样方法。
在参数选择上面,没有使用多尺度攻击,只采用了32x32x3的attack-space降维方法。对每个样本的攻击,限制在1500迭代次数以内,每次攻击平均花费20分钟。由于在这种情况下,使用二分搜索查找$ c$ 代价太大,所以固定$ c=10$ 。

对Inception-v3进行有目标攻击
有目标攻击时更难的,作者说明,当迭代次数达到20000次时,就可以对一个比较难攻击的样本(分类置信度高的)进行攻击
在数据集选择上,作者选择了一个分类置信度高的一张图片,置信度有97%,其top-5的标签分别时,guillotine(1.15%),pretzel(0.07%),Granny Smith(0.06%),dough(0.01%)。作者选择攻击目标类为grand piano(0.0006%)。
在参数选择上,作者进行了attack-space降维以及多尺度攻击,在2000轮迭代时,从32x32x3增加到64x64x3,在10000轮迭代时,增加到128x128x3。运行了总共20000次迭代。当维度大于32x32x3时,采取了重要性采样的方法。
为了减少最后得到的扰动大小,作者提出了一个trick,在找到一个有效的对抗样本后,对Adam进行reset,然后再操作。其原因如下
我们的loss包含连两个部分$ l_1 = c·f(x,t),l_2 = ||x - x_0||_2^2$ ,$ l_1$ 表示的时原始类别概率$ P_{orig}$ 和目标概率$ P_{target}$ 的距离,当$ l_1=0,P_{orig}\le P_{target}$ 的时候,我们就找到了第一个有效的对抗样本,作者观察到,当$ l_1$ 在到达0之前,$ l_2$ 一直再增加。当$ l_1=0$ 以后,按理说$ l_2$ 应该要减小,来减小损失函数,但是,作者发现,$ l_2$ 依然在一直在增加,这可能是因为历史梯度的积累造成的,所以在这时对Adam进行reset。

5. Conclusion and Future Work
这篇论文提出了一种新型的黑盒攻击方法,叫做ZOO,其不需要训练任何substitute model。通过利用零阶优化来估计梯度,就能够在黑盒模型上进行梯度下降。实验显示,该方法的效果与C&W attack相似,且在黑盒攻击上性能远超基于substitute model的方法,因为我们的方法没有任何迁移所造成的损失。同时,提出了一些优化的方法。
作者提出了一些可能的研究方向
- Accelerated black-box attack:看实验结果就知道,ZOO攻击的非常慢,在优化阶段,ZOO需要进行更多次数的迭代,而且在估计梯度上需要进行大量的计算。除了作者提到的击中加速方法,还有一种数据驱动的方法,即:在攻击时,把这些trick全都考虑进去,这能够让我们的黑盒攻击更有效率。
- Adversarial training using our black-box attack:ZOO可以充当一个独立的DNN鲁棒性的指标
- Black-box attacks in different domains:将ZOO拓展到其他方向,如目标检测等。另外,如何合并数据集的边缘信息以及现存的对抗样本进入到黑盒攻击方法中,是一个值得研究的问题。