一、模型介绍
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。
集成学习一般结构为:先产生一组“个体学习器”(individual learner),再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据产生。
集成学习包括:
同质集成的个体学习器,也称为“基学习器”,即由同种类型的个体学习器集成得到的。
异质继承的个体学习器,也称为“组件学习器”,是由不同类型的个体学习器继承得到的。
集成学习,主要可以分为三大类,Boosting,Bagging, Stacking。Boosting的代表有AdaBoost,GDBT, xgboost。而Bagging的代表则是随机森林 (Random Forest)。
1、Boosting
Boosting 是一族可以将弱学习器提升为强学习器的算法。
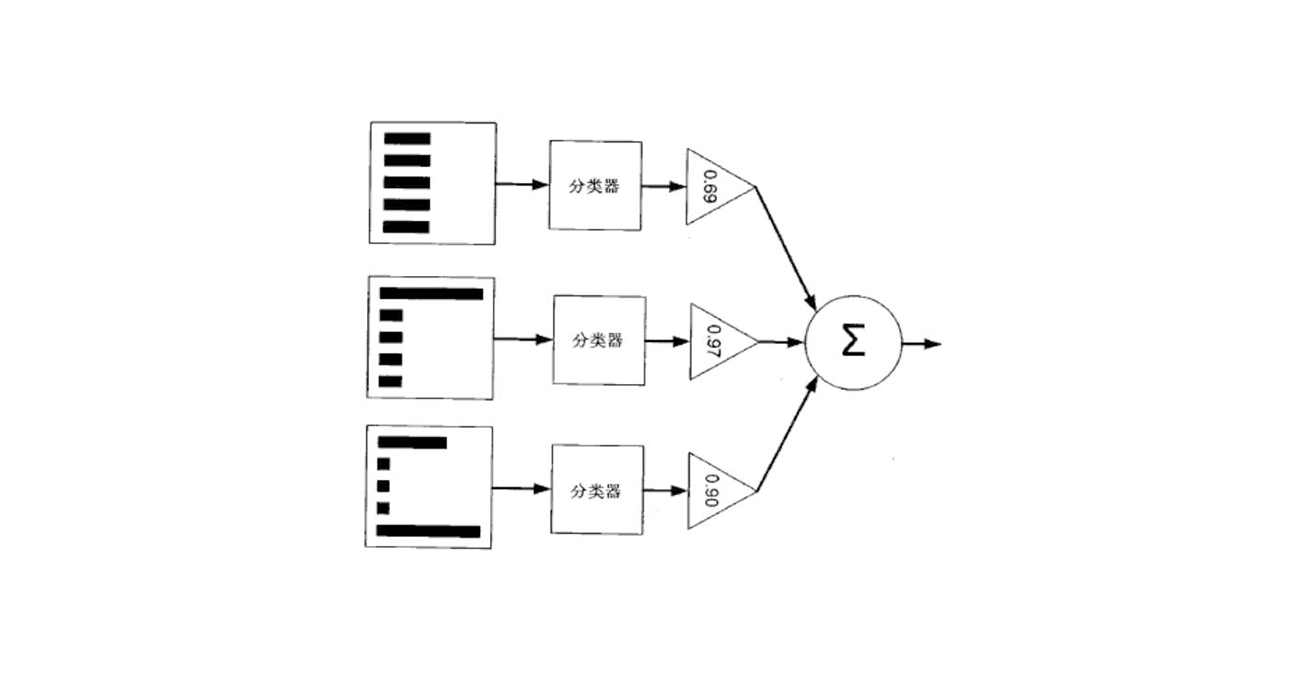
这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基分类器,如此重复进行,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。
1)AdaBoost
AdaBoost方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。AdaBoost方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概率。如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它被选中的概率就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。通过这样的方式,AdaBoost方法能“聚焦于”那些较难分(更富信息)的样本上。虽然AdaBoost方法对于噪声数据和异常数据很敏感。但相对于大多数其它学习算法而言,却又不会很容易出现过拟合现象。
AdaBoost是一种”加性模型”,即基学习器的线性组合:
整体要做的事情,就是最小化指数损失函数:
训练过程
最初,训练集会有一个初始的样本权值分布(平均分布),基于训练集$ D$ 与该分布$ D_t$ 训练一个基学习器$ h_t$ ,估计$ h_t$ 的分类误差,根据误差确定分类器$ h_t$的权重,根据误差等信息重新确定样本的权值分布$ D_{t+1}$ (为分类错误的样本增加权重),伪代码如下图所示:

具体的公式推导,请查看博主博客—集成学习之AdaBoost
2)GDBT
提升树模型是以分类树或回归树为基本分类器的提升方法,其采用加法模型和前向分布算法。基于处理过程中所使用的损失函数的不同,我们有用平方误差损失函数的回归问题,使用指数损失函数的分类问题,以及一般损失函数的一般决策问题。
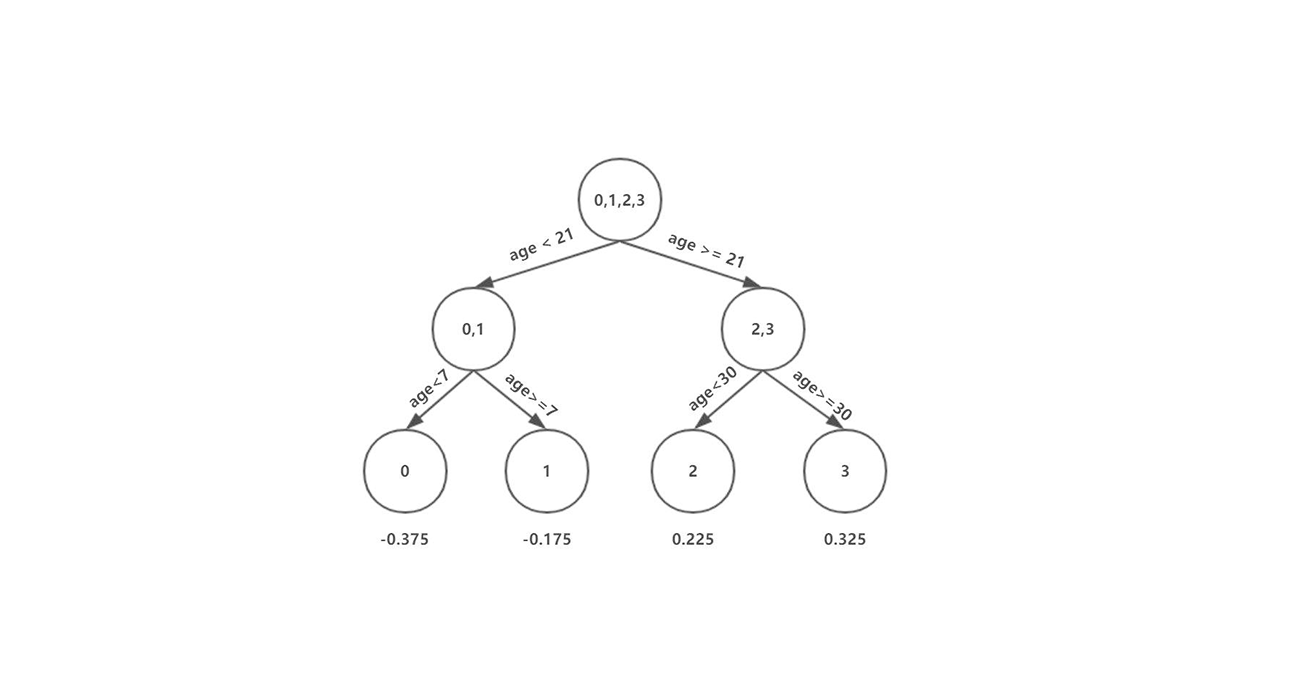
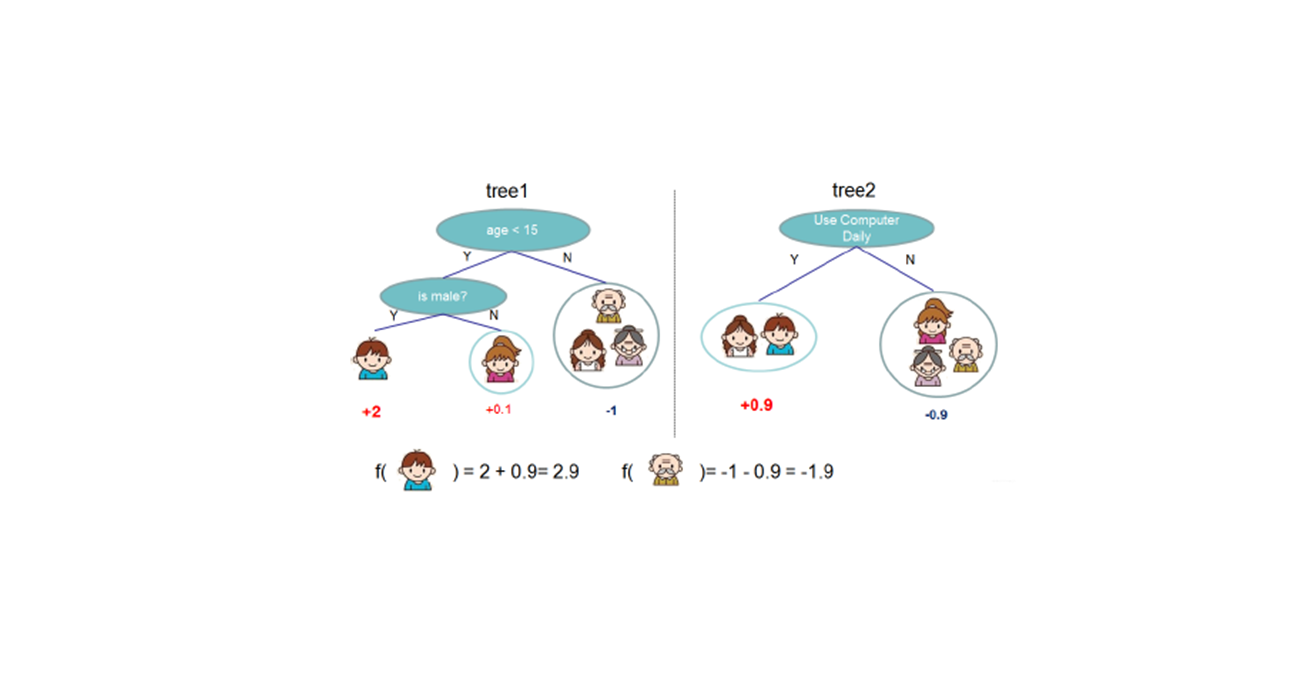
GDBT(Gradient Descent Boosting Tree),梯度提升树,是以回归树为基本分类器的提升方法。是一种基于残差的处理方法,常用来处理回归类问题。
提升树模型可以表示为决策树的加法模型:
其中,$ T(x;\Theta_m)$ 表示第m颗决策树,$ \Theta_m$ 表示决策树的参数,$ M$ 表示树的个数。
在GDBT中采用的损失函数为平方差损失函数:
训练过程
首先初始化$ f_0(x)=0$ ,初始化第一个残差数据集$ r_i=y_i-f_0(x_i)$ (原数据集),根据原数据建立一颗回归树$ T(x;\Theta_0)$ ,根据回归树得到的结果,再次计算残差,将这次得到的残差作为下一颗回归树的数据集,得到回归树$ T(x;\Theta_m)$ ,并且更新$ f_m(x) = f_{m-1}(x)+T(x;\Theta_m)$ ,不断地迭代,我们就能够得到最终的集成模型:

具体的GDBT详解,请查看博主博客—集成学习之GDBT
3)XGBoost
XGBoost的全称是 eXtremeGradient Boosting,2014年2月诞生的专注于梯度提升算法的机器学习函数库,作者为华盛顿大学研究机器学习的大牛——陈天奇。他在研究中深深的体会到现有库的计算速度和精度问题,为此而着手搭建完成 xgboost 项目。xgboost问世后,因其优良的学习效果以及高效的训练速度而获得广泛的关注,并在各种算法大赛上大放光彩。
在我们使用GDBT时,我们采用多次小步的迭代方式来拟合我们的集成模型,GDBT只利用了训练集的一阶信息,这使得我们拟合的速度比较慢,这就造成了我们在训练时可能会生成大量的树模型。为了解决这个问题,XGBoost,采用了训练集的二阶信息,加快了拟合速度,同时修改了在属性划分时的规则,提高了精度。
具体的GDBT详解,请查看博主博客—集成学习之XGBoost
2、Bagging
Bagging是并行集成学习方法最著名的代表,Bagging要求”不稳定“(指数据集的小的变动能够使得分类结果显著的变动)的分类方法,比如:决策树、神经网络。
Bagging通过自主采样法,从包含m个样本的数据集中,采样出T个含m个训练样本的采样集,然后基于每一个采样集训练出一个基学习器,再将这些基学习器进行结合。
Bagging通常对分类任务使用简单投票法,对回归任务采用简单平均法,其算法描述如下图:

1)随机森林
随机森林(Random Forest 简称RF),是Bagging的一个拓展变体。RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性,而在RF中,对决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分,这里参数k控制了随机性的引入程度。当k=d时,基决策树跟传统决策树相同;k=1时,则是随机选择一个属性用于划分;一般情况下推荐$ k=log_2d$
优点:RF简单,容易实现,计算开销小,性能强大。它的多样性不仅来自于样本扰动,还来自于属性扰动,这使得它的泛化性能进一步上升。
缺点:它在训练和预测时都比较慢,而且如果需要区分的类别很多时,随机森林的表现并不会很好
3、Stacking
Stacking是一种将模型输出作为特征,再送入训练器进行分类的一种算法,其主要的算法流程如下:
- 在训练集D上,使用一种集成策略(AdaBoost,GBDT,RF等都可以),训练出T个基学习器
- 利用这T个基学习器,对训练集上的每一个样本进行预测,对于第$ i$ 个样本的输出$ x_1,x_2,…,x_T$ ,将其作为一个新的样本,新样本的标签就是原始训练集上第$ i$ 个样本的标签。这样,就产生了一个新的训练集$ D’$
以$ D’$ 为训练集,训练一个新的分类器
上面的Stacking只做了一层,我们可以做好多层。但是层数并不是越多越好,一般一两层就够了。这其实也是一种集成学习的结合策略。

二、其他需知
1、结合策略
当我们使用集成学习训练出多个基分类器后,我们要使用结合策略来对多个基分类器的结果进行结合
1)平均法
对于数值型输出$ h_i(x)\in \mathbb{R}$ ,最常见的结合策略就是平均法
简单平均法
加权平均法
2)投票法
对于分类任务来说,学习器$ h_i$ 将从类别标记集合$ {c_1,c_2,…,c_N}$ 中预测出一个标记,最常见的结合策略就是投票法。我们将$ h_i$ 在样本$ x$ 上的预测输出表示成一个N维向量$ (h_i^1(x);h_i^2(x);…h_i^N(x);)$ ,其中$ h_i^j(x)$ 是$ h_i$ 在类别标记$ c_j$ 上的输出。
绝大多数投票法
相对多数投票法
加权投票法
3)学习法
上面讲到的Stacking方法
2、集成学习的好处
- 从统计的方面来看,由于学习任务的假设空间往往很大,可能有多个假设在训练集上达到同等性能,此时若但学习器的泛化性能往往不佳,而我们对其进行集成后,集成后的学习器的拟合空间将会变大,会增加学习器的泛化性能。
- 从计算的方面来看,学习算法往往会陷入局部极小,有的局部极小点所对应的泛化性能可能会很糟糕,而通过多次运行之后进行结合,可降低陷入糟糕局部极小点的风险
- 从表示的方面来看,某些学习任务的真实假设可能不在当前学习算法所考虑的假设空间中,此时若使用但学习器则肯定无效,而通过结合多个学习器,由于假设空间有所扩大,所以就有可能学的更好的近似。同第一点。
参考链接
- AdaBoost算法详解
- 周志华老师的《机器学习》