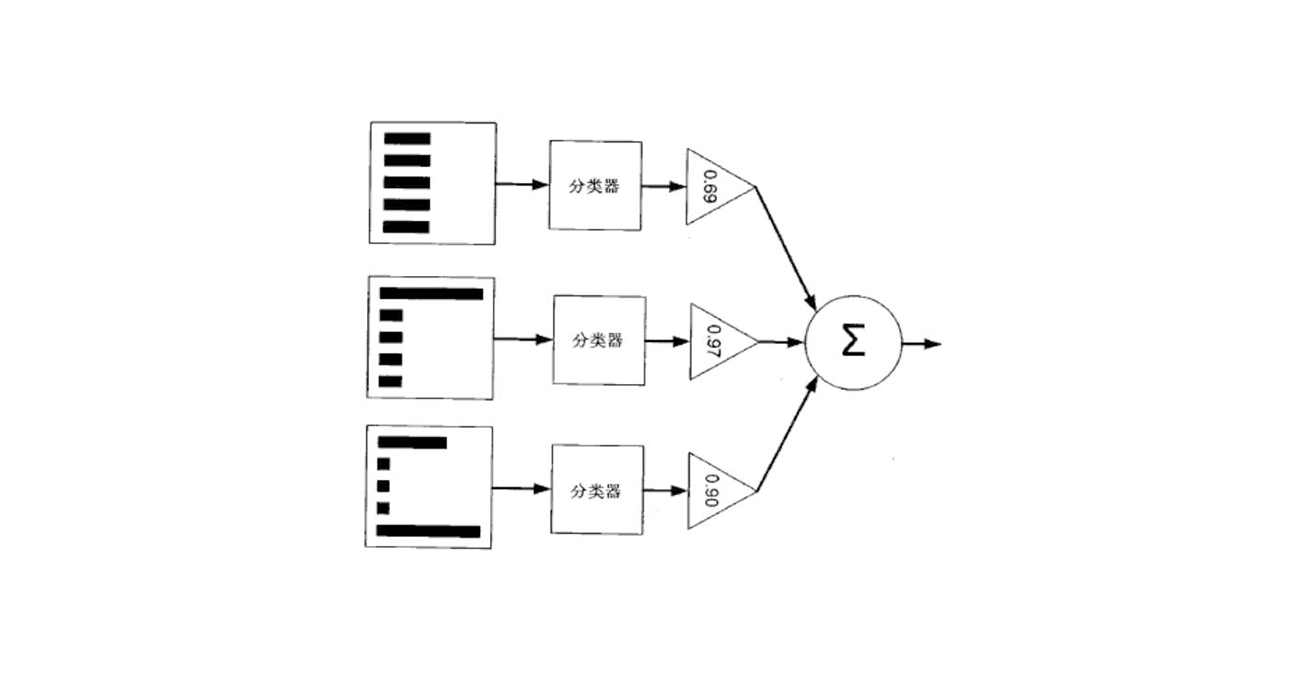
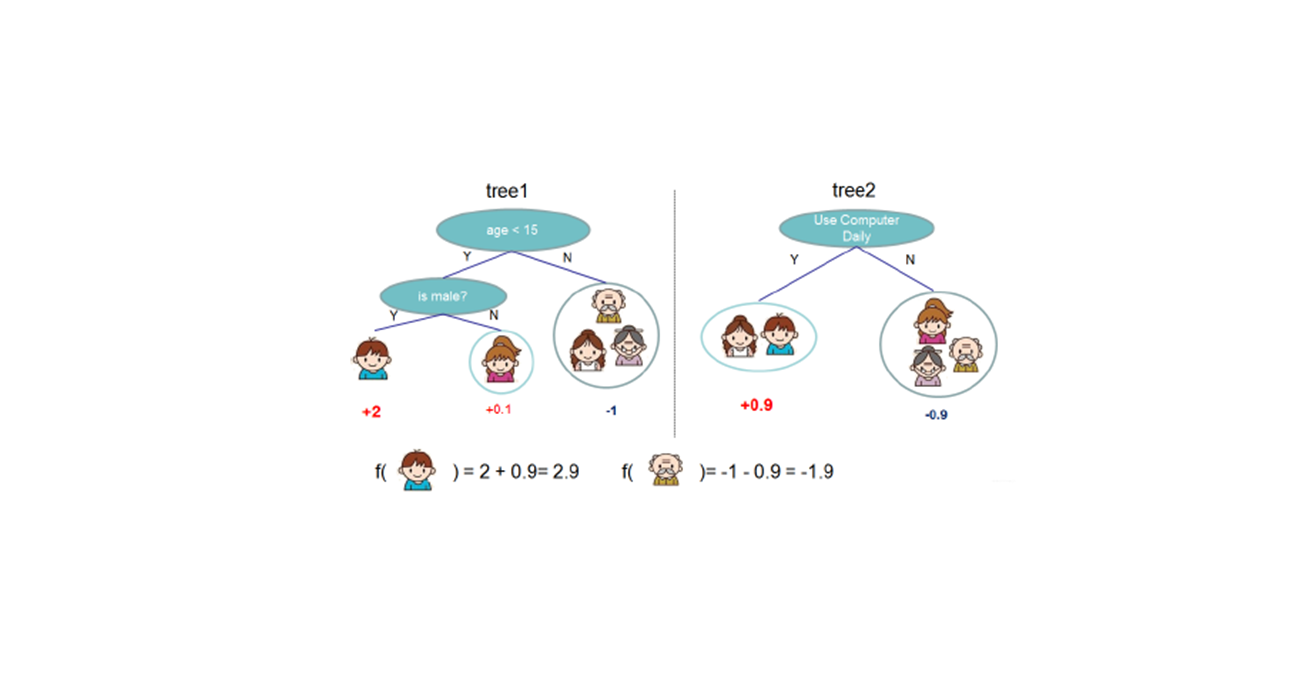
一、模型介绍
提升树模型是以分类树或回归树为基本分类器的提升方法,其采用加法模型和前向分布算法。基于处理过程中所使用的损失函数的不同,我们有用平方误差损失函数的回归问题,使用指数损失函数的分类问题,以及一般损失函数的一般决策问题。
GDBT(Gradient Descent Boosting Tree),梯度提升树,是以回归树为基本分类器的提升方法。是一种基于残差的处理方法,常用来处理回归类问题。
提升树模型可以表示为决策树的加法模型:
其中,$ T(x;\Theta_m)$ 表示第m颗决策树,$ \Theta_m$ 表示决策树的参数,$ M$ 表示树的个数。
在GDBT中采用的损失函数为平方差损失函数:
1、算法思想
GBDT的前向分布算法为:
在前向分布算法的第m步,给定当前模型$ f_{m-1}(X)$ ,我们要求解:
当我们采用平方误差损失函数是,我们要求求解的目标为:
这里,我们记$ r=y-f_{m-1}(x)$ ,就是当前模型拟合数据的残差,所以,对于回归问题的提升树算法来说,我们只需要简单的拟合当前模型的残差就行。那么回归问题的提升树算法叙述如下:
首先初始化$ f_0(x)=0$ ,初始化第一个残差数据集$ r_i=y_i-f_0(x_i)$ (原数据集),根据原数据建立一颗回归树$ T(x;\Theta_0)$ ,根据回归树得到的结果,再次计算残差,将这次得到的残差作为下一颗回归树的数据集,得到回归树$ T(x;\Theta_m)$ ,并且更新$ f_m(x) = f_{m-1}(x)+T(x;\Theta_m)$ ,不断地迭代,我们就能够得到最终的集成模型:

2、GDBT对提升树的优化
上面我们所提到的其实只是提升树在回归问题的求解过程而已,并不是真正的GDBT,对于提升树而言,当损失函数是平方损失或指数损失函数时,每一步的优化是很简单的,但是对于一般的损失函数而言,他的优化过程就比较难,我们很难找到最优的$ \Theta_m$ ,此时,我们就是用梯度下降的近似方法来近似其最优解。修改后的算法过程如下:
首先初始化$ f_0(x) =c$ ,即初始化它为能够使损失函数最小的一个常数值。第二步,将损失函数的负梯度作为当前模型的值,将它作为残差的估计,拟合一个树。得到这棵树的叶节点区域$ R_{mj}$ ,之后利用线性搜索来估计叶节点区域的值$ c_{mj}$,使损失函数最小化(这一步的意思就是,给叶子节点分配合适的值,使得损失函数最小化)。然后更新回归树$ f_m(x)$ ,不断地迭代,直到输出最终模型。

3、示例
我们所做的工作是年龄预测,所用到的用户特征包括购物金额、上网时长、上网时间、百度提问等等。 为了简单起见,我们的训练集只有四个人,A,B,C,D。他们的年龄分别是14,16,24,26。以这个为例,我们来看一下GDBT是如何运作的。
第一步:我们使用原始数据建立一个回归树

我们可以根据回归的结果,计算这A、B、C、D的残差,分别是14-15=-1、16-15=1、24-25=-1、26-25=1,将残差作为训练集训练下一颗回归树

根据回归的结果,计算这A、B、C、D的残差,发现都是0,我们可以退出迭代了。
在这一个提升书的构建过程中,我们只迭代了两次,使用了两个树,得到了我们的集成模型,下面我们看看,我们如何根绝模型得到结果。
将A作为输入,模型的第一棵树输出15,然后模型的第二棵树输出-1。最后对A的预测结果为15+(-1)=14。因此我们的模型对A的预测结果为14。
至此,GBDT终
4、注意
当我们直接使用残差来拟合回归树时,很容易造成过拟合。为了减少过拟合的危险,我们会给残差加一个学习率$ \alpha$ ,即在构建一个新的决策树时,我们使用的训练集为$ \alpha ·r$ ,通过这样多次迭代的方式,来最终生成我们的集成模型
参考链接
- 李航老师的《统计机器学习》
- GBDT详解