1. 写代码之前要做的事情
训练神经网络前,别管代码,先从预处理数据集开始。我们先花几个小时的时间,了解数据的分布并找出其中的规律。
Andrej有一次在整理数据时发现了重复的样本,还有一次发现了图像和标签中的错误。所以先看一眼数据能避免我们走很多弯路。
由于神经网络实际上是数据集的压缩版本,因此您将能够查看网络(错误)预测并了解它们的来源。如果你的网络给你的预测看起来与你在数据中看到的内容不一致,那么就会有所收获。
一旦从数据中发现规律,可以编写一些代码对他们进行搜索、过滤、排序。把数据可视化能帮助我们发现异常值,而异常值总能揭示数据的质量或预处理中的一些错误。
2.设置端到端的训练评估框架
处理完数据集,接下来就能开始训练模型了吗?并不能!下一步是建立一个完整的训练+评估 框架。
在这个阶段,我们选择一个简单又不至于搞砸的模型,比如线性分类器、CNN,可视化损失。获得准确度等衡量模型的标准,用模型进行预测。
1)固定随机种子
使用固定的随机种子,来保证运行代码两次都获得相同的结果,消除差异因素。
2)简单化
在此阶段不要有任何幻想,不要扩增数据。扩增数据后面会用到,但是在这里不要使用,现在引入只会导致错误。
3)绘制测试集损失
在绘制测试集损失时,对整个测试集进行评估,不要只绘制批次测试损失图像,然后用Tensorboard对它们进行平滑处理。
4)在初始阶段验证损失函数
验证函数是否从正确的损失值开始。例如,如果正确初始化最后一层,则应在softmax初始化时测量-log(1/n_classes)。
5)初始化
正确初始化最后一层的权重。如果回归一些平均值为50的值,则将最终偏差初始化为50。如果有一个比例为1:10的不平衡数据集,请设置对数的偏差,使网络预测概率在初始化时为0.1。正确设置这些可以加速模型的收敛。
6)人类基线
监控除人为可解释和可检查的损失之外的指标。尽可能评估人的准确性并与之进行比较。或者对测试数据进行两次注释,并且对于每个示例,将一个注释视为预测,将第二个注释视为事实。
7)设置一个独立于输入的基线
最简单的方法是将所有输入设置为零,看看模型是否学会从输入中提取任何信息。
8)过拟合一个batch
增加了模型的容量并验证我们可以达到的最低损失。
9)验证减少训练损失
尝试稍微增加数据容量。
10)在训练模型前进行数据可视化
将原始张量的数据和标签可视化,可以节省了调试次数,并揭示了数据预处理和数据扩增中的问题。
11)可视化预测动态
在训练过程中对固定测试批次上的模型预测进行可视化。
12)使用反向传播来获得依赖关系
一个方法是将第i个样本的损失设置为1.0,运行反向传播一直到输入,并确保仅在第i个样本上有非零的梯度。
3.挑选模型
首先我们得有一个足够大的模型,它可以过拟合,减少训练集上的损失,然后适当地调整它,放弃一些训练集损失,改善在验证集上的损失)
1)挑选模型
为了获得较好的训练损失,我们需要为数据选择合适的架构。不要总想着一步到位。如果要做图像分类,只需复制粘贴ResNet-50,我们可以在稍后的过程中做一些自定义的事。
2)Adam方法是安全的
在设定基线的早期阶段,使用学习率为3e-4的Adam 。根据经验,Adam对超参数更加宽容,包括不良的学习率。
3)一次只复杂化一个
如果多个信号输入分类器,建议逐个输入,然后增加复杂性,确保预期的性能逐步提升,而不要一股脑儿全放进去。比如,尝试先插入较小的图像,然后再将它们放大。
4)学习率设置
初始的学习率肯定是有一个最优值的,过大则导致模型不收敛,过小则导致模型收敛特别慢或者无法学习
可以采用搜索法,从小到大开始训练模型,记录损失的变化,比如从1e-5增大到1
也可以采用预设规则学习率变化法,见的策略包括fixed,step,exp,inv,multistep,poly,sigmoid等
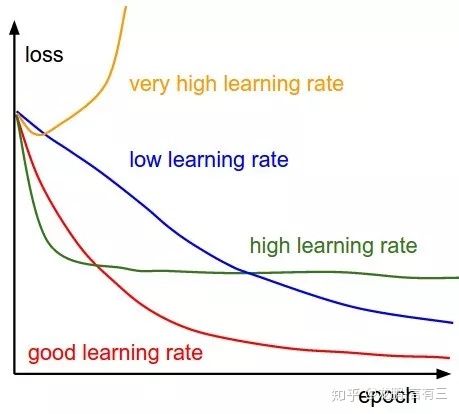
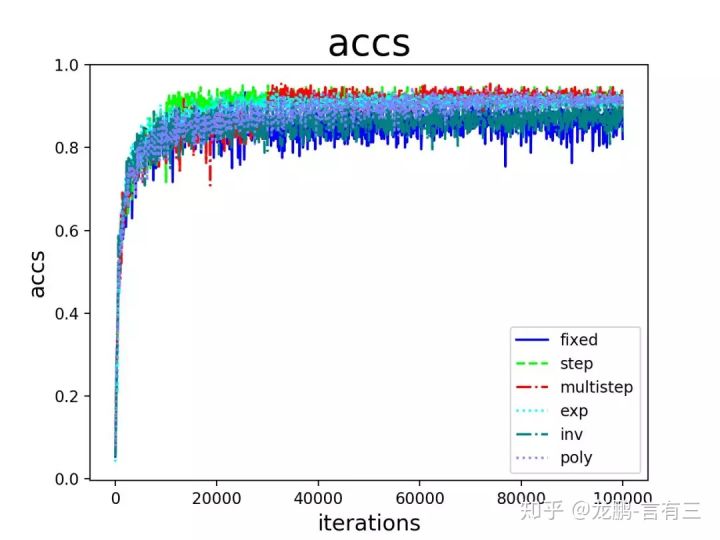
从结果来看:
- step,multistep方法的收敛效果最好,这也是我们平常用它们最多的原因。虽然学习率的变化是最离散的,但是并不影响模型收敛到比较好的结果。
- 其次是exp,poly。它们能取得与step,multistep相当的结果,也是因为学习率以比较好的速率下降,虽然变化更加平滑,但是结果也未必能胜过step和multistep方法,在这很多的研究中都得到过验证,离散的学习率变更策略不影响模型的学习。
- inv和fixed的收敛结果最差。这是比较好解释的,因为fixed方法始终使用了较大的学习率,而inv方法的学习率下降过程太快。
实验证明通过设置上下界,让学习率在其中进行变化,可以在模型迭代的后期更有利于克服因为学习率不够而无法跳出鞍点的情况。
5)每轮训练数据乱序
每轮数据迭代保持不同的顺序,避免模型每轮都对相同的数据进行计算。
6)batch_size选择
模型性能对batchsize虽然没有学习率那么敏感,但是在进一步提升模型性能时,batchsize就会成为一个非常关键的参数。
- 大的batchsize减少训练时间,提高稳定性,导致模型泛化能力下降
对于小数据量的模型,可以全量训练,这样能更准确的朝着极值所在的方向更新。但是对于大数据,全量训练将会导致内存溢出,因此需要选择一个较小的batch_size。如果这时选择batch_size为1,则此时为在线学习,每次修正方向为各自样本的梯度方向修正,难以达到收敛。batch_size增大,处理相同数据量的时间减少,但是达到相同精度的轮数增多。实际中可以逐步增大batch_size,随着batch_size增大,模型达到收敛,并且训练时间最为合适。
7)学习率和batchsize的关系
通常当我们增加batchsize为原来的N倍时,要保证经过同样的样本后更新的权重相等,按照线性缩放规则,学习率应该增加为原来的N倍[5]。但是如果要保证权重的方差不变,则学习率应该增加为原来的sqrt(N)倍[7],目前这两种策略都被研究过,使用前者的明显居多。
从两种常见的调整策略来看,学习率和batchsize都是同时增加的。学习率是一个非常敏感的因子,不可能太大,否则模型会不收敛。同样batchsize也会影响模型性能,那实际使用中都如何调整这两个参数呢?
研究表明,衰减学习率可以通过增加batchsize来实现类似的效果,这实际上从SGD的权重更新式子就可以看出来两者确实是等价的,文中通过充分的实验验证了这一点。
研究表明,对于一个固定的学习率,存在一个最优的batchsize能够最大化测试精度,这个batchsize和学习率以及训练集的大小正相关。
对此实际上是有两个建议:
- 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
- 尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整
4.正则化
理想的话,我们现在有一个大模型,在训练集上拟合好了。
现在,该正则化了。舍弃一点训练集上的准确率,可以换取验证集上的准确率。
1)获取更多数据
至今大家最偏爱的正则化方法,就是添加一些真实训练数据。
不要在一个小数据集花太大功夫,试图搞出大事情来。有精力去多收集点数据,这是唯一一个确保性能单调提升的方法。
2)数据扩增
把数据集做大,除了继续收集数据之外,就是扩增了。旋转,翻转,拉伸,做扩增的时候可以野性一点。
可参考数据增强方法
3)有创意的扩增
还有什么办法扩增数据集?比如域随机化 (Domain Randomization) ,模拟 (Simulation) ,巧妙的混合 (Hybrids) ,比如把数据插进场景里去。甚至可以用上GAN。
4)预训练
当然,就算你手握充足的数据,直接用预训练模型也没坏处。
5)跟监督学习死磕
不要对无监督预训练太过兴奋了。至少在视觉领域,无监督到现在也没有非常强大的成果。虽然,NLP领域有了BERT,有了会讲故事的GPT-2,但我们看到的效果很大程度上还是经过了人工挑选。
6)输入低维一点
把那些可能包含虚假信号的特征去掉,因为这些东西很可能造成过拟合,尤其是数据集不大的时候。
同理,如果低层细节不是那么重要的话,就输入小一点的图片,捕捉高层信息就好了。
7)模型小一点
许多情况下,都可以给网络加上领域知识限制 (Domain Knowledge Constraints) ,来把模型变小。
比如,以前很流行在ImageNet的骨架上放全连接层,但现在这种操作已经被平均池化取代了,大大减少了参数。
8)减小批尺寸
对批量归一化 (Batch Normalization) 这项操作来说,小批量可能带来更好的正则化效果 (Regularization) 。
9)Dropout
给卷积网络用dropout2d。不过使用需谨慎,因为这种操作似乎跟批量归一化不太合得来。
10)权重衰减Weight Decay
增加权重衰减 (Weight Decay) 的惩罚力度。
L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。
11)早停法Early Stop
不用一直一直训练,可以观察验证集的损失,在快要过拟合的时候,及时喊停。
12)附加
大模型很容易过拟合,几乎是必然,但早停的话,模型可以表现很好。
最后的最后,如果想要更加确信,自己训练出的网络,是个不错的分类器,就把第一层的权重可视化一下,看看边缘 (Edges) 美不美。
如果第一层的过滤器看起来像噪音,就需要再搞一搞了。同理,激活 (Activations) 有时候也会看出瑕疵来,那样就要研究一下哪里出了问题。
5.调参
1)随机网格搜索
在同时调整多个超参数的情况下,网格搜索听起来是很诱人,可以把各种设定都包含进来。
但是要记住,随机搜索才是最好的。
直觉上说,这是因为网络通常对其中一些参数比较敏感,对其他参数不那么敏感。
如果参数a是有用的,参数b起不了什么作用,就应该对a取样更彻底一些,不要只在几个固定点上多次取样。
2)超参数优化
世界上,有许多许多靓丽的贝叶斯超参数优化工具箱,很多小伙伴也给了这些工具好评。
但我个人的经验是,State-of-the-Art都是用实习生做出来的 (误) 。
6.测试阶段
1)模型融合
2)TTA测试时增强
测试时将原始数据做不同形式的增强,然后取结果的平均值作为最终结果
提高了结果的稳定性和精准度.
参考博客
https://zhuanlan.zhihu.com/p/64864995


%20%20Pandas%E5%B8%B8%E7%94%A8%E6%93%8D%E4%BD%9C/cover.jpg?raw=true)
%20%20%E9%9D%A2%E8%AF%95%E5%B0%8F%E7%9F%A5%E8%AF%86(1)/cover.jpg?raw=true)
%20%20Matplotlib%E5%B8%B8%E7%94%A8%E6%93%8D%E4%BD%9C/cover.jpg?raw=true)
%20%20%E9%9D%A2%E8%AF%95%E5%B0%8F%E7%9F%A5%E8%AF%86(2)/cover.jpg?raw=true)
