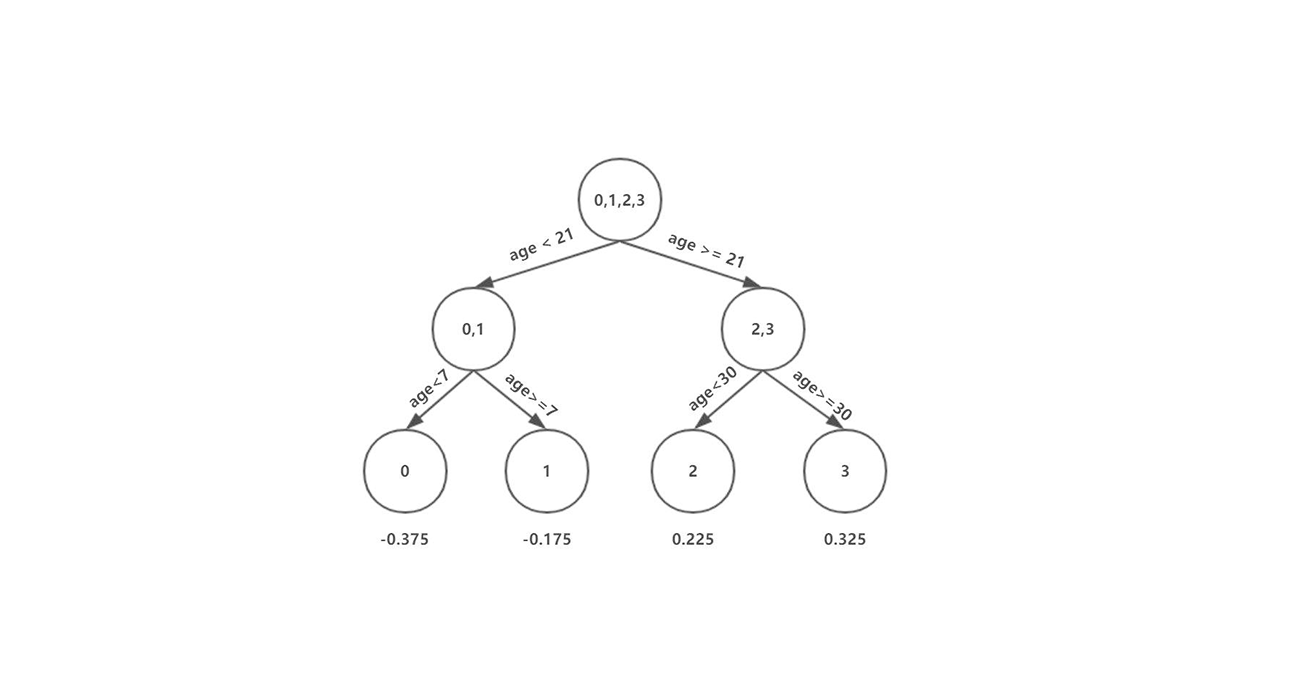
1、模型介绍
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。
Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。
1.1 模型
对于模型输入$ x$ ,模型参数$ w$ ,模型输出$ h(x) $ ,预测结果$ y\in{0,1}$
其中$ g(x)$ 是Sigmoid函数,其函数形式如下:
其中$ C$ 是一个常数,是分类阈值,通常取0.5
1.2 模型训练过程
- 将模型输入$ x$ 输入线性单元,得到输出$ z = w^Tx$ 。将$ z$ 输入Sigmoid函数,将线性值映射到[0,1]区间内
- 根据$ h(x)$ 与$ label$ ,利用极大似然估计得到Loss,根据Loss得到参数更新的梯度
- 利用梯度下降方法更新参数
1.3 交叉熵损失函数
在Logistic回归中,我们常用的损失函数为交叉熵损失函数,该损失函数也正是利用极大似然估计而生成的Loss函数
将上面的函数进行整合,我们可以得到如下形式
2、模型分析
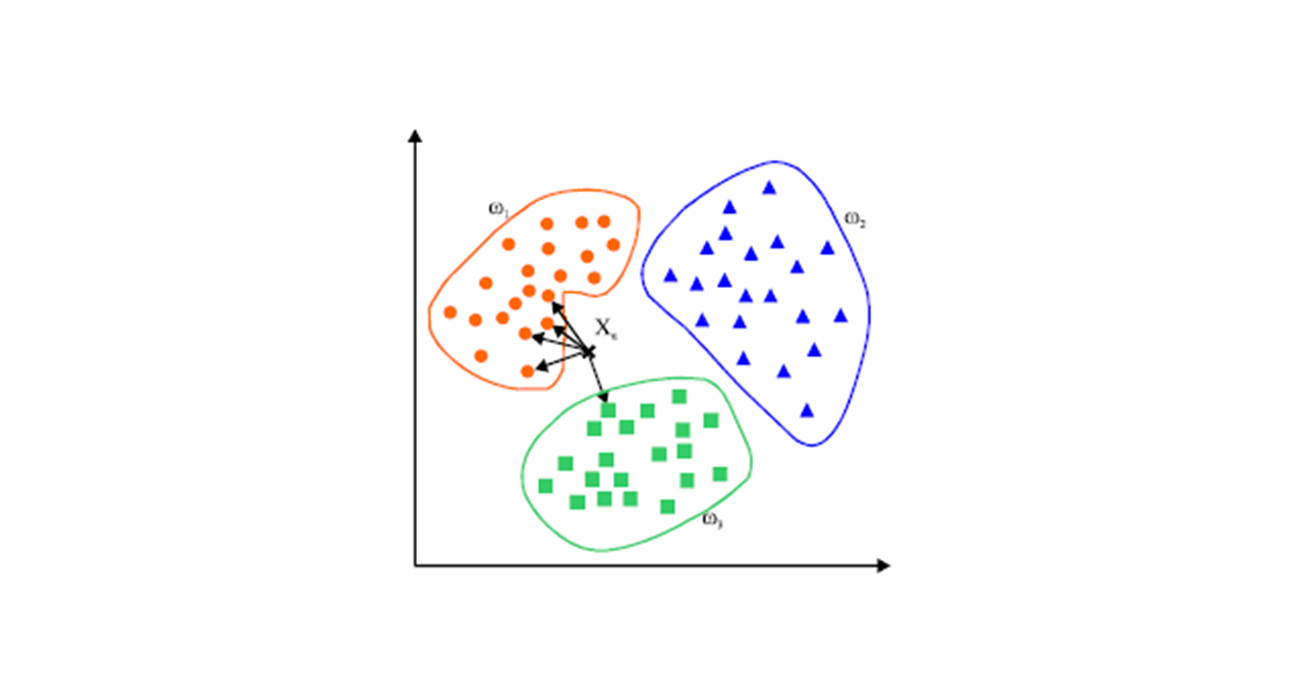
2.1 决策边界
Logistic回归,是一个线性的决策边界,如图:

2.2 逻辑回归与线性回归
逻辑回归(Logistic Regression)与线性回归(Linear Regression)都是一种广义线性模型(generalized linear model)。逻辑回归假设因变量 y 服从伯努利分布,而线性回归假设因变量 y 服从高斯分布。 因此与线性回归有很多相同之处,去除Sigmoid映射函数的话,逻辑回归算法就是一个线性回归。可以说,逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题。
2.3 模型优缺点
优点
- 直接对分类可能性进行建模,无需实现假设数据分布,这样就避免了假设分布不准确所带来的问题。
- 形式简单,模型的可解释性非常好,特征的权重可以看到不同的特征对最后结果的影响。
- 除了类别,还能得到近似概率预测,这对许多需利用概率辅助决策的任务很有用。
缺点
- 准确率不是很高,因为形式非常的简单,很难去拟合数据的真实分布。
- 本身无法筛选特征
2.4 模型应用
- Logistic回归可以应用于二分类任务
- 多个Logistic回归,可以进行多分类任务的求解
2.5 Tips
- 在对模型进行训练前,要对数据进行充分的处理,可以将数据离散化等,数据离散化可以加快训练速度,提高对异常值的鲁棒性
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 BaiDing's blog!



评论