Deep Learning based Recommender System: A Survey and New Perspectives
时间:2017年
关键词:Recommender systems · Deep learning · Survey
论文位置:https://arxiv.org/pdf/1707.07435.pdf
引用:Zhang S, Yao L, Sun A, et al. Deep learning based recommender system: A survey and new perspectives[J]. ACM Computing Surveys (CSUR), 2019, 52(1): 1-38.
摘要: 随着在线信息量的不断增长,推荐系统已成为克服此类信息过载的有效策略。鉴于推荐系统在许多web应用程序中的广泛应用,以及它对改善与过度选择相关的许多问题的潜在影响,无论怎样强调推荐系统的效用都不为过。近年来,深度学习在计算机视觉和自然语言处理等许多研究领域引起了广泛的兴趣,这不仅是因为它具有优异的性能,而且还具有从头开始学习特征表示的实用性。深度学习的效果也很普遍,最近在信息检索和推荐系统研究中证明了它的有效性。显然,推荐系统中的深度学习领域正在扩大。本文旨在对基于深度学习的推荐系统的最新研究成果进行全面综述。更具体地说,我们提供并设计了一个基于深度学习的推荐模型的分类法,同时提供了最新技术的全面总结。最后,我们对当前的趋势进行了扩展,并提供了与该领域新的令人兴奋的发展相关的新视角
索引- 推荐系统、深度学习、调查
这篇综述从分类器的角度出发进行综述调查
1、Introduction
略
2、Related work
深度学习实践的成功很大的影响了推荐系统的研究方向。最初,Salakhutdinov等人(2007)提出了一种在电影推荐任务中使用CF的深层分层模型的方法。自从这项基础研究以来,已经有很多将深度模型应用到推荐系统研究中的尝试。通过利用深度学习在提取隐藏特征和关系方面的有效性,研究人员提出了替代性的解决方案来解决推荐问题,包括准确性、稀疏性和冷启动问题。Sedhain等人(2015)在自动编码器的帮助下,通过预测用户-矩阵的缺失评分来获得更高的准确度,Devoght和Bersini(2017)利用神经网络通过将CF转换为序列预测问题来提高短期预测精度。Wang等人(2015b)提出了一个使用CF的深层模型,通过学习大量的representation来处理稀疏问题。此外,深层模型被用来处理可伸缩性问题,因为这些模型在降维和特征提取方面非常有用。Elkahky等人(2015)提出了一种利用深度神经网络从高维特征中获取低维特征的可伸缩性解决方案,Louppe(2010)利用深度学习进行降维处理大数据集。
目前深层架构的流行,使得我们有必要回顾和分析推荐系统研究中关于深度学习的现有研究。综合分析可以帮助和指导愿意在这一领域工作的研究人员。尽管有这种迫切的需要,就我们所知,只有四项研究正在调查这一课题。Zheng 等人 (2016)调查和评论了最先进的深度推荐系统。然而,这项调查研究包含的出版物数量不足,导致对整个概念的看法非常有限。Betru等人(2017)解释传统推荐系统和深度学习方法。这项调查的范围也不充分,因为它只分析了三种出版物。Liu and Wu(2017)分析了基于深度学习的推荐方法,并提出了一个分类框架,该框架根据输入和输出方面对程序进行分类。作者在有限的方向上解释了这项研究。然而,我们提出的工作为更准确地理解基于深度学习的技术在推荐系统中的使用提供了指导。
最近,Zhang 等人(2017a)发布了一份关于基于深度学习的推荐系统的全面调查。虽然这篇论文中参考的论文数量挺多并且这项研究非常接近,但是在分类方法跟我们这篇论文存在差异。Zhang 等人(2017a)只关注出版物的结构分类,并提出两个方面的方案(神经网络模型和集成模型),我们提供了一个四维分类(神经网络模型、提供的补救措施、应用领域和目的属性)。此外,在检查出版物时,我们不想深入研究实现细节,而是更愿意对这一主题有一个大致的了解,并为愿意为推荐系统进行深入学习的研究人员带路。我们的工作使对这个主题感兴趣的学者能够理解在推荐系统中使用深度学习技术的主要效果。这篇综述性研究集中在了解推荐系统中使用每种基于深度学习的方法的动机。此外,它的目的是对提供的基于深度学习的解决方案的见解,以应对当前推荐系统的挑战。
3、Background
推荐系统可以定义为一种特殊的信息过滤系统,深度学习是机器学习的一种发展趋势。在研究这两个领域如何结合在一起之前,有必要先复习一下这两个学科的基础知识。在这个背景部分中,我们将简要介绍推荐系统的基本原理、主要类型和主要挑战。然后,我们通过解释推动深度学习成为计算机科学新兴领域的因素,引入了深度学习的概念。最后,我们举例说明了在机器学习中广泛应用的深度学习模型
3.1 Recommender systems
在一个典型的推荐系统中,推荐问题是双重的,即(i)估计单个项目的预测或(ii)通过预测对项目进行排序。推荐方法主要分为基于内容的推荐算法、协同过滤推荐算法、混合推荐算法。除了这些推荐系统,还有一些特别的技术,比如context-aware推荐系统将上下文信息融合进入推荐过程中,tag-aware推荐系统将产品标签与标准CF算法相结合,trust-based推荐系统考虑了用户之间的信任关系,group-based推荐系统侧重于在用户组级别上个性化推荐。
3.1.1 Collaborative filtering recommender systems
CF是推荐系统中最重要的一种方法,它假设人们在未来会与过去有着相似的口味。在这样的系统中,志同道合的邻居用户的偏好形成了所有推荐的基础,而不是项目的个别特征。
CF系统的主要参与者是主动用户$ a$ ,该用户寻求项目的评分预测或排名。通过利用过去的偏好作为确定用户之间相关性的指标,C依赖于给定用户的口味来进行推荐。
通常,一个CF系统包括m个用户$ U = {u_1,u_2,…,u_m}$ ,以及n个项目$ P = {p_1,p_2,…,p_n}$ 。这个系统构成了一个$ m \times n$ 的用户-项目矩阵,其包含的是用户给项目的打分。在对用户$ a$ 推荐项目$ q$ 时,CF算法会预测$ q$ 的评分,或者为用户$ a$ 推荐最好的top-N项目。
CF算法主要有以下两种方法:
- Memory-based algorithms :利用整个用户-项目矩阵来识别相似的实体。在确定了最近邻的用户后,这些实体的过去的打分被用来进行推荐。基于记忆的算法可以是user-based, item-based, or hybridized. 在user-based中,使用的是用户$ a$ 的最近邻的过去的喜好。在item-based中,使用的是与$ q$ 相似的项目的评分。
- Model-based algorithms :这种方法的目的是使用机器学习和数据挖掘技术建立一个仿射模型,建立和训练这样的模型可以进行在线CF任务的预测。基于模型的CF算法包括贝叶斯模型、聚类模型、决策树和奇异值分解模型。
3.1.2 Content-based recommender systems
基于内容的推荐系统根据项目的画像(profile)和用户的画像生成推荐(Van Meteren和Van Someren 2000)。在基于内容的筛选中,主要目的是推荐与用户过去喜欢的项目相似的项目。例如,如果用户喜欢一个包含“stack”、“queue”和“sorting”等关键字的网站,基于内容的推荐系统会建议与数据结构和算法相关的页面
当向系统推荐添加新的项目时,基于内容的过滤非常有效。虽然新项目没有评分历史记录,但该算法可以从描述性信息中获益并推荐给相关用户。例如,一部新的科幻电影可能会被推荐给之前看过并喜欢电影《终结者》和《黑客帝国》的用户。
虽然基于内容的推荐系统能够有效地推荐新的商品,但是由于没有足够的用户信息,它们无法产生个性化的预测。此外,由于算法没有利用来自志同道合用户的社区知识(Lops et al。2011年)。
3.1.3 Hybrid recommender systems
CF系统和基于内容的推荐者都有其独特的优点和缺点。另一方面,混合推荐系统将CF和基于内容的方法结合起来,通过利用另一种方法的优点来避免每种方法的局限性。一个典型的混合场景是在CF推荐系统中,针对一个新项目,在没有任何用户评分的情况下,使用基于内容的项目描述信息进行评分(Tran and Cohen 2000)。人们提出了各种混合技术,可概括如下(Burke 2002):
- Weighted :一个单一的推荐输出是由不同的推荐方法组合而成的
- Switching :根据当前情况,这两种算法都有选择地生成推荐输出。
- Mixed :同时显示两种方法的推荐输出。
- Cascade :一种方法产生的建议输出由另一种方法改进。
- Feature combination :这两种方法的特征在一个单独的算法中被结合和利用。
- Feature augmentation :一种方法的推荐输出被用作另一种方法的输入
3.1.4 Challenges of recommender systems
尽管推荐系统提供了解决信息过载问题的有效方法,但它们也带来了许多不同的挑战(Su和Khoshgoftaar 2009;Bobadilla等人。2013年)。在本节中,我们将简要描述推荐系统中的主要问题,包括准确性、稀疏性、冷启动和可伸缩性。
推荐系统的一个关键要求是给用户带来刺激和相关的信息。用户对系统的信任程度直接关系到推荐的质量。如果用户没有得到满意的产品和服务,推荐引擎可能会被认为在客户满意度方面不够充分,这使得用户很明显需要寻找替代系统。因此,推荐系统必须满足一定的预测精度,才能提高推荐系统的偏好性和有效性。准确度作为推荐系统讨论最多的挑战,通常通过三种方法进行研究,即评分预测、使用预测和项目排名(Shani和Gunawardana 2011)
CF系统依赖于系统用户给出的项目评分历史。稀疏性似乎是一个主要的问题,尤其是对于CF来说,因为用户只对可用项目的一小部分进行评分,这使得生成预测具有挑战性(Su和Khoshgoftaar 2009;Bobadilla等人。2013年)。在处理稀疏数据集时,CF算法可能无法利用用户和项目之间的有益关系。数据稀疏导致了另一个严重的挑战,称为冷启动问题。由于没有足够的数据来描述他们,因此不可能为一个收视率很低的新用户生成预测。同样,将最近添加的项目作为建议提交给用户也无法实现,因为这些项目缺乏评级。然而,与CF技术不同,新添加的用户和项目可以通过利用其内容信息在基于内容的推荐系统中进行管理
大多数推荐系统都部署在响应环境中。在一个典型的推荐场景中,用户在浏览网页时,会根据自己的喜好为其提供一组推荐项目。为了有效地执行这样的场景,建议应该在合理的时间内提供,这需要一个高度可扩展的系统(Linden等人。2003年)。随着系统中用户和/或项目数量的增长,许多算法往往会减慢速度或需要更多的计算资源(Shani and Gunawardana 2011)。因此,可伸缩性就变成了一个需要有效管理的重大挑战
3.2 Deep learning
介绍了受限玻尔兹曼机(RBM)、深度置信网络(DBN)、自动编码器、RNN、CNN。这里不做赘述。
4、Perspectival synopsis of deep learning within recommender systems
深度学习技术在推荐系统领域的应用是一个非常流行的主题。深度学习很擅长从多个数据源中分析数据,并从中发现隐藏的特征。随着大数据设备和超级计算机的发展,深度学习技术的数据处理能力不断提高,推荐系统中的深度学习技术已经成为研究者们的研究热点。他们利用深度学习技术,为推荐系统的挑战(如可伸缩性和稀疏性)提供实用的解决方案。此外,他们还利用深度学习来产生推荐、降维、从不同数据源提取特征并将其集成到推荐系统中。在推荐系统中,使用深度学习技术对用户-项目偏好矩阵或内容/侧面信息进行建模,有时两者都是。Table 1展示了在数据建模实践中使用深度学习技术的出版物。(PS:由于该篇论文的引用问题,朋友们还是从论文中去找Table 1吧)
4.1 Deep learning techniques for recommendation
在这一节中,我们将分析在推荐系统中如何以及为了什么目的使用深度学习方法。本节介绍的技术包括RBMs、DBNs、自动编码器、RNN和CNN。此外,在其他技术小节中还分析了一些不太传统的方法。
4.1.1 Restricted Boltzmann machines for recommendation
RBM是玻耳兹曼机的一种特殊类型,他们有两层网络,一层是可见的softmax层,一层是隐藏层。在RBM中,不存在层内通信。在推荐领域中,RBM被用来提取用户偏好或项目平分中的隐藏特征(Salakhutdinov等人。2007;邓等。2017年)。RBMs还用于联合建模用户投票项目之间的相关性和投票特定项目的用户之间的相关性,以提高推荐系统的准确性(Georgiev and Nakov 2013)。RMBs也被用来group-based的推荐系统中,通过联合建模集合特征和组轮廓来建模组的偏好(Hu et al. 2014)
Truyen等人(2009)利用Boltzmann机器中隐藏层和softmax层之间的连接以及softmax层单元之间的连接,来提取一个评分项目与其评分的联系,以及评分项目之间的相关性。在推荐系统中,Boltzmann机器被用来模拟物品或用户之间的成对相关性。此外,Gunawardana和Meek(2008)不仅使用Boltzmann机器来建模用户和项目之间的关联,而且还用于整合内容信息。他们把机器的参数和内容信息联系起来。
RBMs主要用于提供用户偏好的低阶表示。另一方面,Boltzmann机器用于整合用户或项目对之间的相关性,以及可见层中的邻域形成。通过RBMs结合用户-用户和项目-项目相关性是可能的,方法是生成一个混合模型,其中隐藏层连接到两个可见层(一个用于项目,一个用于用户)(Georgiev和Nakov 2013)。然而,使用Boltzmann机器对成对用户或项目相关性和邻域形成进行建模具有更高的精确度(Georgiev和Nakov 2013)。由于RBMs比Boltzmann机器具有更直接的参数化和更大的可扩展性,因此在考虑成对用户和项目相关性时,它们可能更可取(Georgiev和Nakov 2013)。RBMs还允许处理大型数据集。此外,RBMs和Boltzmann机器都可以集成来自不同数据源的辅助信息。
4.1.2 Deep belief networks for recommendation
在推荐系统领域,DBN的一个应用是侧重于从音频内容中提取隐藏的和有用的特征,来进行基于内容的和混合音乐推荐(Wang and Wang 2014) 。DBN也被用在了文本数据的推荐领域中(Kyo-Joong et al. 2014; Zhao et al. 2015) 。此外,DBN作为一个分类器被用在基于内容的推荐系统中,来分析用户的偏好,特别是在文本数据中(Kyo-Joong et al. 2014) 。通过利用DBN,我们可以提取单词中的语义信息(Zhao et al. 2015)。另外,DBN也可以被用来从用户偏好的低阶特征中提取高阶特征(Hu et al. 2014) 。这些研究解释了,DBN主要是被用来提取特征和进行分类任务,特别是在文本和音频领域。
4.1.3 Autoencoders for recommendation
一个简单的自动编码器用编码器部分压缩给定的数据,并通过解码器从压缩版本重建数据。自动编码器试图通过降维操作重建初始数据。这种类型的深层模型被用于推荐系统中,学习用户-矩阵的非线性表示,并通过确定缺失值来重构它(Ouyang et al.2014年;Sedhain et al.2015年)。自动编码器也用于降维,并通过使用编码器部件的输出值提取更多的潜在特征(Deng et al 2017;Zuo et al. 2016年;Unger et al. 2016年)。此外,稀疏编码被应用到自动编码器中,以学习更有效的特征(Zuo et al。2016年)
DAE是自动编码器的一种特殊形式,输入数据被破坏以防止成为恒等的网络(即输入等于输出)。SDAE是简单的将许多自动编码器堆叠在一起。这些自动编码器提供了提取更多隐藏特征的能力。DAE在推荐系统中用于预测损坏数据中的缺失值(Wu et al.2016b),SDAEs帮助推荐系统找出更密集的输入矩阵形式(Strub和Mary 2015)。此外,通过允许来自多个数据源的数据,它们也有助于将辅助信息集成到推荐系统中(Wang et al.2015a,b;L et al.2015年;Strub et al. 2016;Ying et al. 2016;Wei et al. 2017年)。Wang et al. (2015b)利用贝叶斯SDAE,而Li et al.(2015)利用边缘化的DAE将辅助信息集成到他们的推荐系统中。Wang et al.(2015a)还通过生成SDAE的概率形式来提出关系SDAE,以将辅助数据与评级相结合。由于边缘化的DAE比DAE具有更高的可扩展性和更快的速度,它成为推荐系统中一个有吸引力的深度学习工具。在(Wang et al. 2015b)中,辅助数据仅在输入层集成。不像(Wang et al. 2015b),辅助信息被集成到SDAE的每一层(Strub et al. 2016年)。在(Strub et al. 2016;Wei et al. 2017),使用自动编码器从辅助数据中提取特征,并与概率矩阵分解和timeSVD++等CF方法紧密耦合(Strub等人。2016年)和(Wei等人。2017),分别解决稀疏问题。Ying等人。(2016)利用SDAEs提取边信息的潜在特征,并将其集成到成对排序模型的Bayesian框架中。
该领域的研究表明,与RBMs相比,自动编码器提供更准确的建议。造成这种情况的原因之一是,RBMs通过最大化对数似然来生成预测,而自动编码器则通过最小化均方根误差(RMSE)来生成预测,而RMSE是最常用的公序系统精度度量之一。此外,由于采用了基于梯度的反向传播方法和RBMs的对比散度等方法,自编码器的训练阶段比RBMs快(Sedhain等人。2015年)。堆叠式自动编码器比非堆叠式自动编码器提供更精确的预测,因为堆叠式自动编码器可以更深入地学习隐藏的特征(Li等人。2015年)。自动编码器在推荐系统中有很多用途,例如特征提取、降维和生成预测。在推荐系统中使用了自动编码器,特别是在处理稀疏性和可伸缩性问题时。
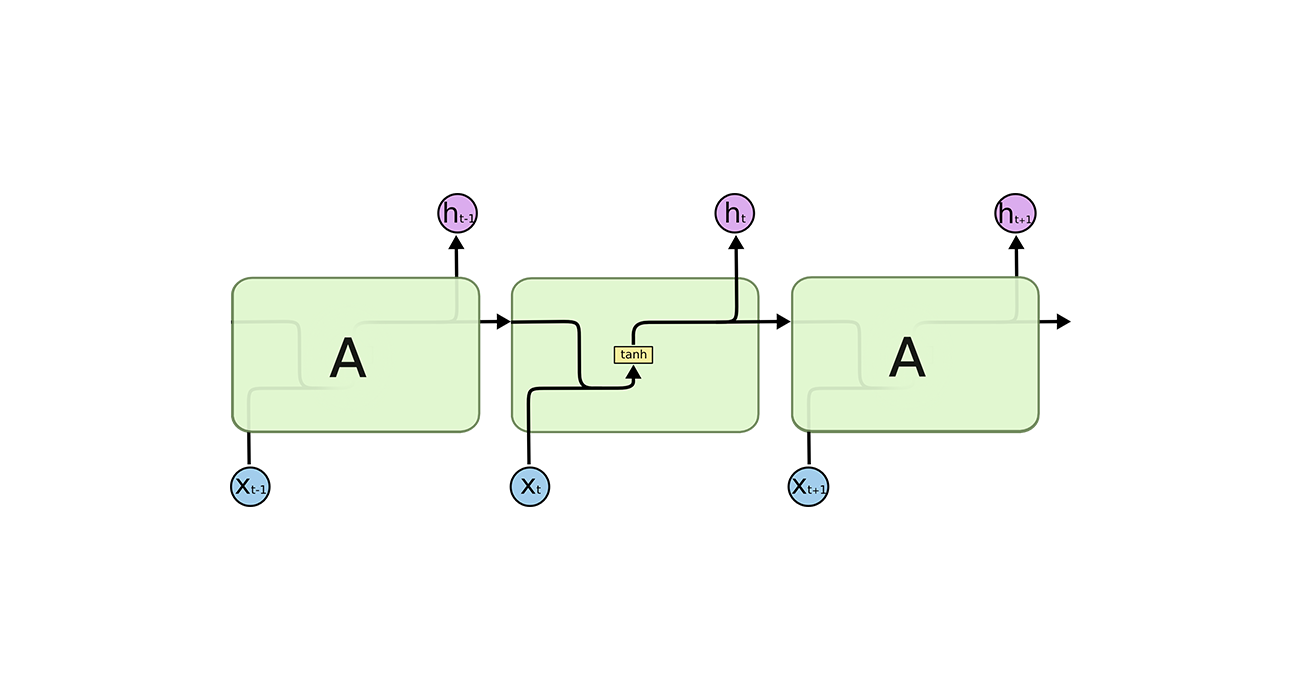
4.1.4 Recurrent neural networks for recommendation
RNN专门用于处理序列信息。在电子商务系统中,用户当前的浏览历史会影响其购买行为。然而,大多数典型的推荐系统会在会话开始时创建用户偏好,从而忽略了当前的历史记录和用户操作的顺序。RNN在推荐系统中被用来整合当前浏览网页的历史记录和视图顺序,以提供更准确的推荐(Wu et al. 2016a;Hidasi et al. 2016a;Tan et al. 2016年)。Wu et al. (2016a)还将RNN的结果与前馈神经网络的结果合并,以在生成预测时考虑用户项的相关性。Ko et al. (2016)利用RNN来表示用户行为的时间、上下文因素,通过将这些表示与用户偏好的潜在因素相结合来改进更准确的建议。
RNN还用于非线性表示用户和项目的潜在特征之间的影响以及它们随时间的共同变化(Dai et al. 2017年)。Devoght和Bersini(2017)利用RNN,将用户口味的演变作为一个序列预测问题来整合到推荐过程中。
通过对推荐系统深度学习的研究,可以得到一些结论。与传统的基于最近邻和矩阵分解的方法相比,RNN对推荐的覆盖率和短期预测(预测下一个消费品)有积极的影响。这种成功源于RNNs对用户品味的演变以及用户和项目潜在特征之间的协同进化(Devooght and Bersini 2017;Dai et al. ,2010年)。2017年)。此外,RNN是一个很好的选择,特别是在基于会话的推荐系统中,并将用户的隐含行为与其偏好相结合。
4.1.5 Convolutional neural networks for recommendation
CNN使用至少一层的卷积,这种类型的神经网络用于特定的任务,如图像识别和对象分类。推荐系统也受益于CNNs。Oord et al. (2013)当无法从用户反馈中获得潜在因素时,利用CNN从音频数据中提取潜在因素。Shen et al. (2016)使用CNNs从文本数据中提取潜在因素。Zhou et al. (2016)提取视觉特征,以生成推荐用户的视觉兴趣档案。Lei et al. (2016)利用CNN提取图像的潜在特征,将特征和用户偏好映射到同一个潜在空间。使用CNNs提取的文本信息的语义也被用于推荐系统中,特别是上下文感知推荐系统,以提供更合格的推荐(Wu et al. 2017b年)。因此,CNN主要用于从数据中提取潜在因素和特征,特别是从图像和文本中提取潜在因素和特征,用于推荐。
4.1.6 Other techniques
Neural autoregressive distribution estimation (NADE)是RBM的另一种形式,它为离散变量提供了可处理的条件分布(Larochelle和Murray 2011)。Zheng et al. (2016b)将NADE应用于CF的用户项偏好。作者提取用户项偏好的条件隐藏表示来产生预测。与基于RBM-based 的CF相比(Salakhutdinov等人。2007),NADE提供了更准确的建议,并且更有效地优化(Zheng et al。2016年b)。Du et al. (2016)利用CF中的NADE,同时对所有用户和项目的评分进行建模。
前向神经网络用于推荐系统中,用于分类和产生预测(Wakita et al. 2016;Cheng et al. 2016;Zhang et al. 2018年)。Zhang et al. (2018)利用多层神经网络,对用户和隐含反馈项之间的交互作用进行非线性建模,对项目进行个性化排序。.
4.2 Remedies for challenges of recommender systems
针对推荐系统所面临的挑战,提出有效的解决方案是将深度学习方法应用于推荐系统的一个方向。在这一部分,我们将分析基于深度学习的研究,为推荐系统的困难提供解决方案。
4.2.1 Solutions for improving accuracy
在推荐系统中采用深度学习技术的主要目的之一是提高预测结果的准确性。由于深度学习技术能够成功地提取隐藏特征,研究人员利用它们来提取潜在因素,深度学习技术有助于及时监控用户口味的演变,有助于提高推荐的质量,在推荐系统中,深度学习通常用于获取用户和物品的特征,生成基于用户和物品的方法或带有偏好信息的辅助信息的联合模型。。讲到的技术包括RBM、SVD、AutoRec、NADE等。
研究表明,深度学习提高推荐准确度的主要原因在于它能够提取隐藏的特征,并将来自不同来源的信息联合起来。不同模型的RMSE值如下,在MovieLens 1M数据集上进行的实验。如下图所示,基于项目的算法比基于用户的算法更精确。这种改进的原因是,每个项目的平均评分数量远远大于每个用户的平均评分数量。

4.2.2 Solutions for sparsity and cold-start problems
基于CF的推荐系统克服稀疏性问题的一个解决方案是利用深度学习技术将高维稀疏用户-项目矩阵转化为低维密集的数据。
在推荐系统中,数据稀疏性问题通常是利用额外的边信息(side information)来进行解决的。然而,由于偏好矩阵和边信息的稀疏性,潜在因子可能不起作用。因此,深度学习技术被用来根据偏好矩阵和边信息提取用户和项目的告诫表示,然后结合矩阵分解来处理稀疏性和冷启动问题(Wang等人2015a,b;Li等人2015年;Oord等人2013;Wang and Wang 2014;Xu等人2017a;Zhang等人2017b;Kim等人2017年)。
在一些研究中,内容信息直接集成到推荐过程中,以处理稀疏性和冷启动问题。稀疏性和冷启动问题主要是利用特征工程的深度学习技术,将从异构数据源中提取的特征集成到推荐过程中。在各种深度学习技术中,自动编码器、CNN和DBNs是最常用的。
4.2.3 Solutions for scalability problem
为了解决可伸缩性问题,研究人员利用深度学习技术提取高维用户偏好和项目评级的低维潜在因素
4.3 Awareness and prevalence over recommendation domains

4.4 Specialized recommender systems and deep learning
专门的推荐系统允许更精确地表示用户和项目之间的关系。在本节中,我们将分析基于深度学习技术的此类专业推荐系统。下表显示了基于深度学习的出版物在专业推荐系统中的分布情况,其中“其他”类别由于出版物数量有限而拥有信任意识和基于群体的推荐系统。

5 Quantitative assessment of comprehensive literature
数据集


6 Insights and discussions
- 深度学习并不专门针对一种独特的推荐方法;它们被用于各种不同目的的推荐方法中。在基于内容的过滤中,这些技术主要用于提取特征,以从异构数据源生成基于内容的用户/项目文件。然而,在CF中,它们通常被用作基于模型的方法来提取用户-项目矩阵上的潜在因素。在混合推荐系统中,利用深度学习方法从辅助信息中提取特征,并将其集成到推荐过程中。
- RNNs主要用于基于会话的推荐,通过将当前用户历史记录集成到他们的偏好中来提高准确性。此外,推荐系统更倾向于使用RNNs来考虑用户随着时间的推移不断变化的品味。 CNNs和DBNs主要用于文本、音频和图像输入的特征工程。提取的特征用于基于内容的过滤技术或作为CF中的辅助信息。
- 深度学习技术被用来处理推荐系统的稀疏性和冷启动问题,方法是从辅助信息中提取特征并将它们集成到用户项目偏好中。此外,基于深度学习的方法被用于将高级和稀疏特征的维数降低为低级和密集特征。
- 因为大多数基于深度学习的推荐方法侧重于提高评级预测或项目排名预测的准确性,用于测量统计准确性的推荐系统中通常使用的评估指标也用于基于深度学习的技术中。评估基于深度学习的推荐方法的典型方法是均方误差(MSE)、平均绝对误差(MAE)和预测精度的均方根误差(RMSE);分类精度的精度、召回率、F1测量值和接收器工作特性( ROC )曲线;以及归一化的非计数累积增益( nDCG ),用于对推荐项目列表进行排名。