
机器学习(十四)隐马尔可夫模型
一、模型介绍 概率图模型是一类用图来表达变量相关关系的概率模型。它以图为表示工具,最常见的是用一个节点表示一个或一组随机变量,结点之间的边表示变量间的概率相关关系,即”变量关系图”。
根据边的性质不同,概率图模型可大致分为两类:第一类 ...

机器学习(十三)EM算法
一、模型介绍 EM(Expectation-Maximum)算法也称期望最大化算法,曾入选“数据挖掘十大算法”中。EM算法是最常见的隐变量估计方法,在机器学习中有极为广泛的用途,例如常被用来学习高斯混合模型(Gaussian mixture model,简称GMM ...
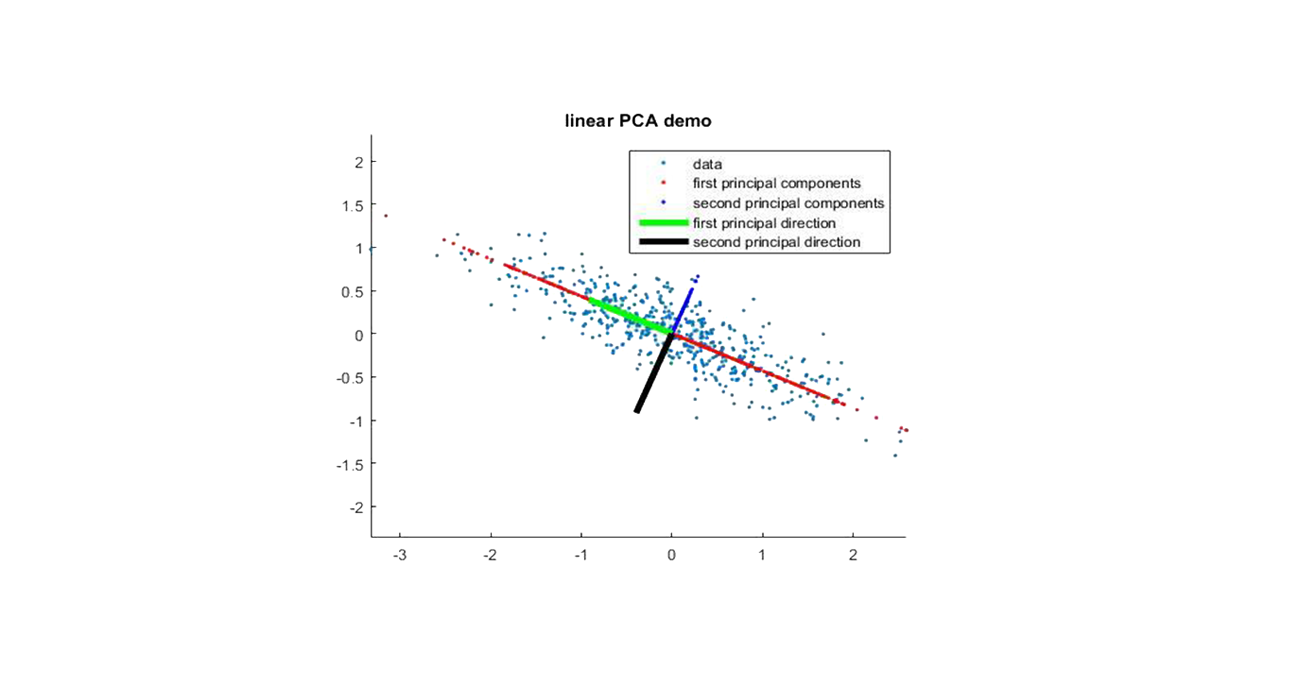
机器学习(十二)PCA
一、模型介绍 PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。
降维就是一种对高维度特征数据预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要 ...
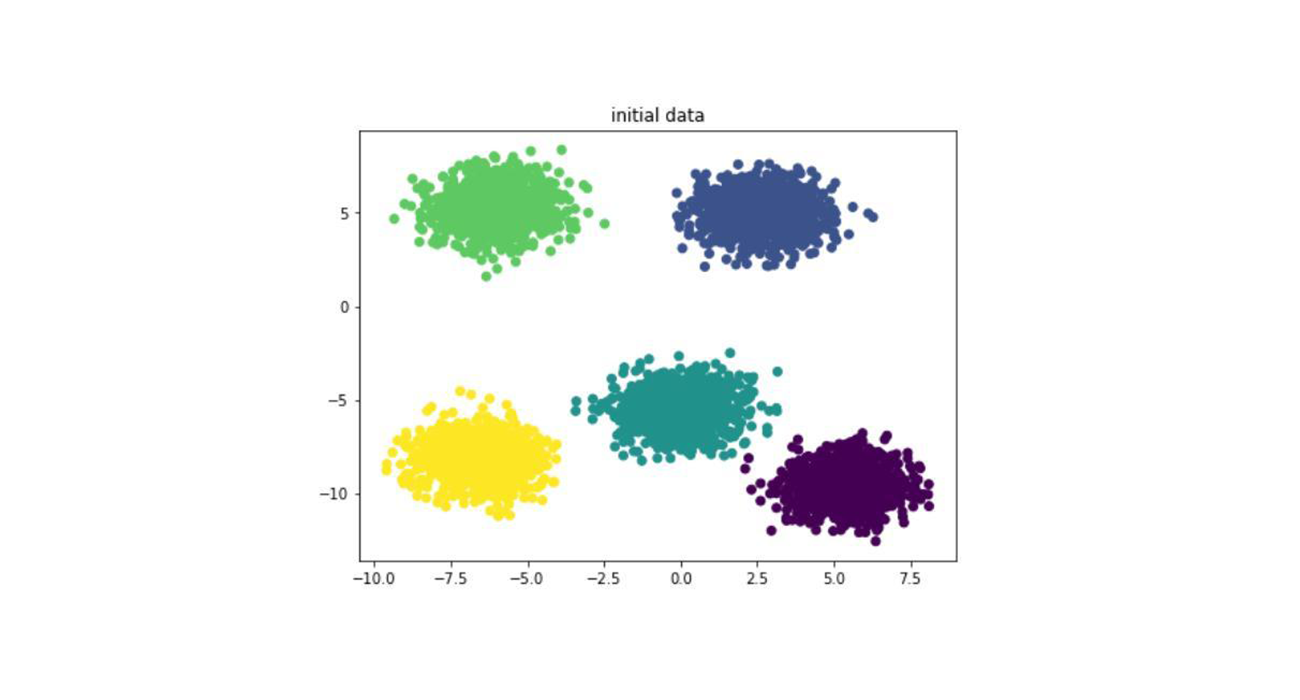
机器学习(十一)K-means
一、模型介绍 k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程 ...
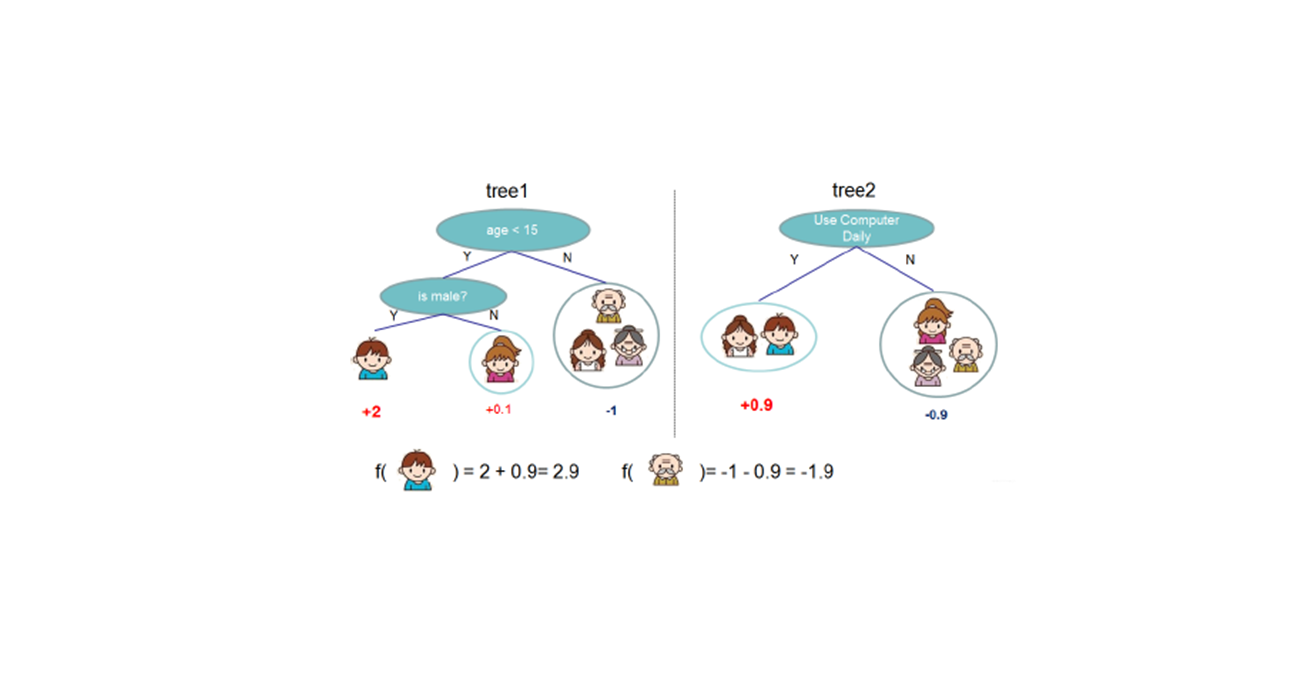
机器学习(十)集成学习之XGBoost
一、模型介绍 XGBoost的全称是 eXtremeGradient Boosting,2014年2月诞生的专注于梯度提升算法的机器学习函数库,作者为华盛顿大学研究机器学习的大牛——陈天奇。他在研究中深深的体会到现有库的计算速度和精度问题,为此而着手搭建完成 x ...
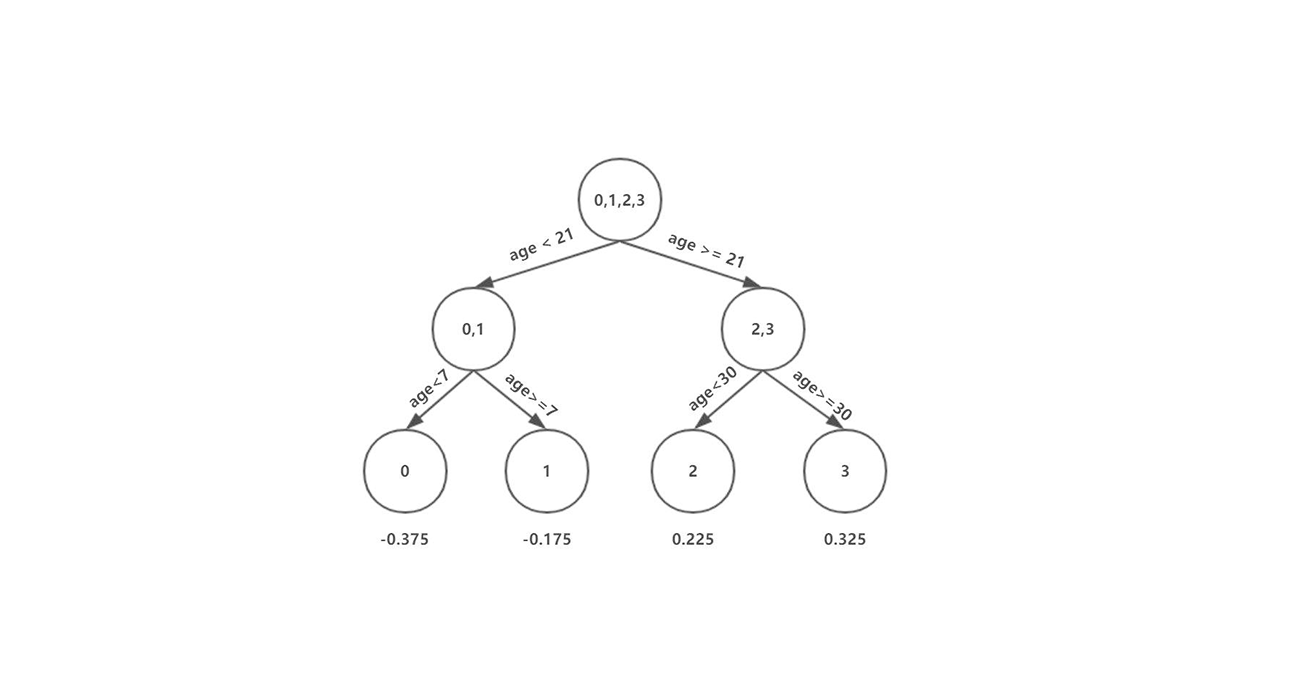
机器学习(九)集成学习之GDBT
一、模型介绍 提升树模型是以分类树或回归树为基本分类器的提升方法,其采用加法模型和前向分布算法。基于处理过程中所使用的损失函数的不同,我们有用平方误差损失函数的回归问题,使用指数损失函数的分类问题,以及一般损失函数的一般决策问题。
...
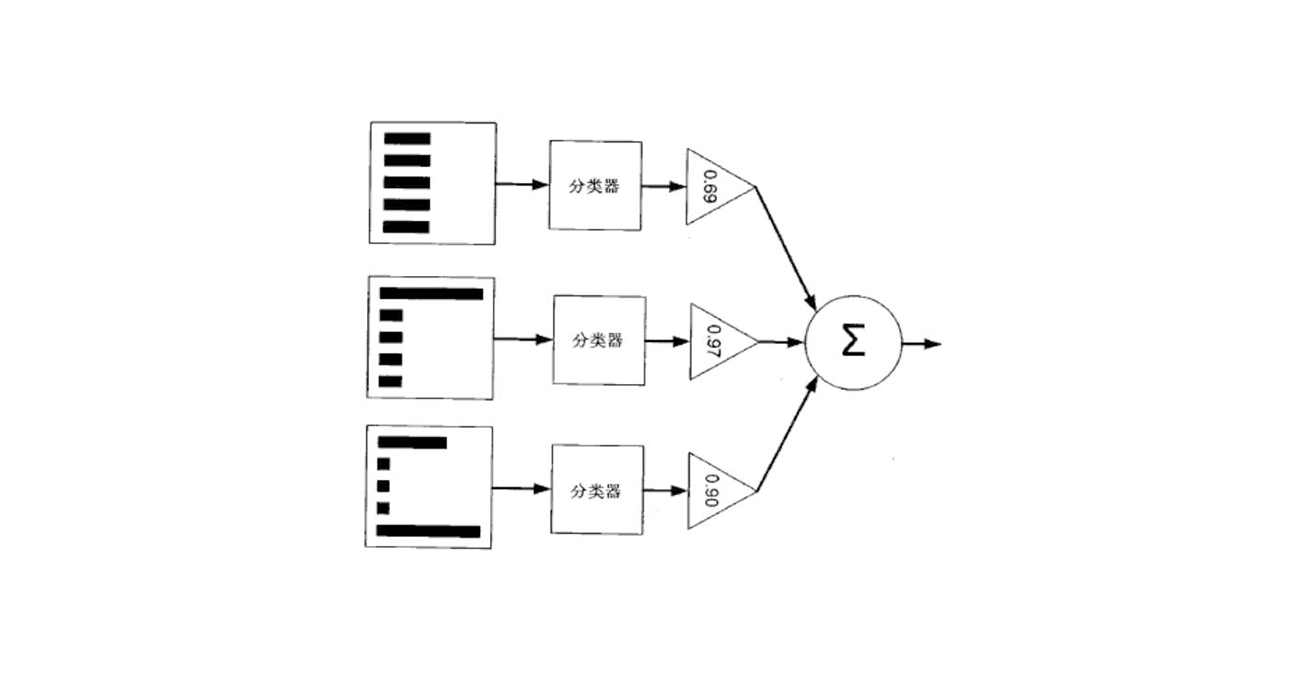
机器学习(八)集成学习之AdaBoost
一、模型介绍 AdaBoost方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。AdaBoost方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概 ...

机器学习(七)集成学习
一、模型介绍 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。
集成学习一般结构为:先产生一组“个体学习器”(individual learner),再用某种策略将它们结合起来。个体学习器通常由一 ...

机器学习(六)贝叶斯分类器
一、模型介绍 贝叶斯分类器是一类分类算法的总称,贝叶斯定理是这类算法的核心,因此统称为贝叶斯分类。下面,我们将会从贝叶斯决策论、极大似然估计、朴素贝叶斯分类器、半朴素贝叶斯分类器、贝叶斯网络来进行讲解。
1、贝叶斯决策论 贝叶斯决策论(B ...
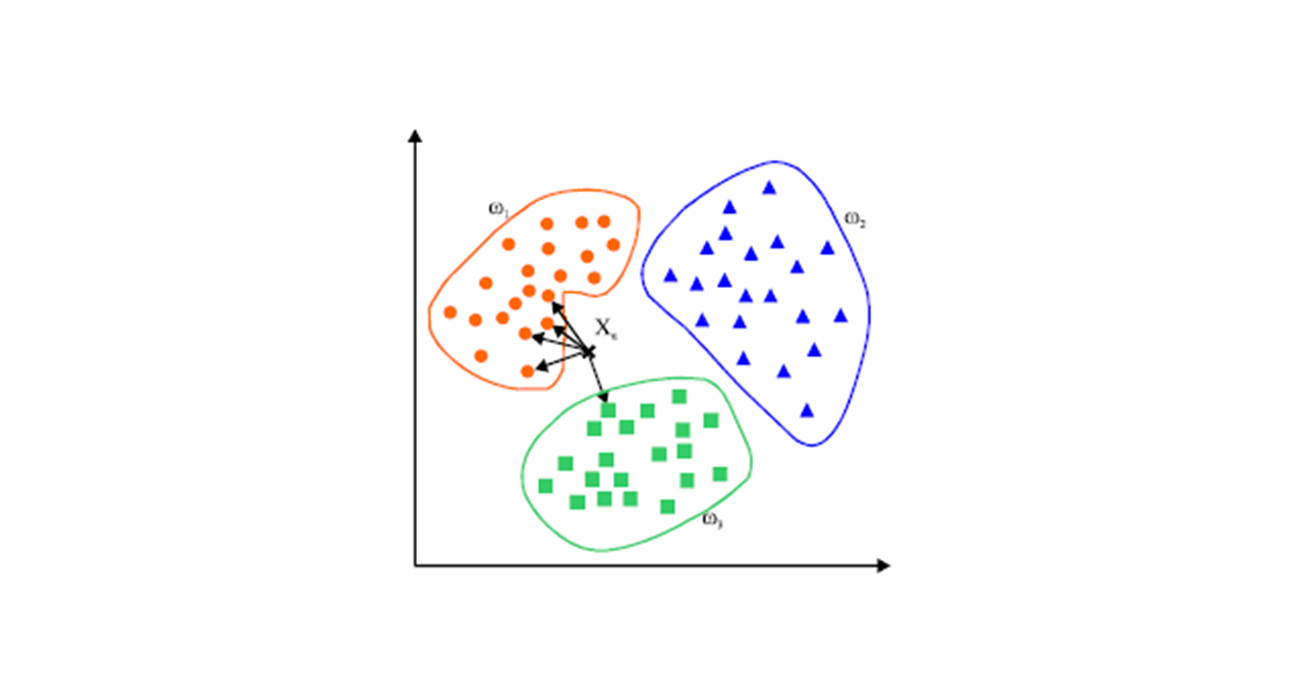
机器学习(五)K近邻算法
1、模型介绍 KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。KN ...
")
")
")

